
스프링이란
- 프레임워크이다.
프레임(틀)워크(동작하다) = 틀 안에서 동작하다 ⇒ 틀 제공해줄테니 벗어나지 말아라 - 오픈소스이다.
- 소스 코드 공개
- 내부 볼 수 있다 = 내부 뜯어 고칠 수 있다
- IoC 컨테이너를 가진다.
- IoC(Inversion of Control): 제어의 역전
- 주도권이 스프링에게 있다
- 개발자 new → heap 메모리 공간에 올리고 여러 메서드에서 사용하고 싶음
⇒ 레퍼런스 변수 주소를 각각의 메소드가 관리 → 공유하는 것이 힘듦 - 클래스로 만든 오브젝트 → 스프링이 스캔해서 읽어서 자기가 객체를 직접 띄움
= 스프링이 읽어서 heap 메모리에 올려줌
- 개발자 new → heap 메모리 공간에 올리고 여러 메서드에서 사용하고 싶음
- Class → 설계도 / Object → 실체화가 가능한 것 / Instance → 실체화된 것
- ex. 캐릭터/가구 - 추상적인 의미 → 실체화 X But, 농담곰/의자, 침대 → 실체화 O ⇒ Object
의자 s = new 의자();
public void make() {
의자 s = new 의자();
}
public void use() {
의자 s = new 의자();
}- DI를 지원한다.
- DI(Dependency Injection): 의존성 주입
- 스프링이 관리하는 객체
→ 원하는 모든 곳(클래스의 메소드)에서 가져와서 사용할 수 있음 (공유해서 사용)- make()와 user()에서 사용하는 의자는 같은 의자 ⇒ 싱글톤으로 가야함
- 엄청나게 많은 필터를 가지고 있다.
- 특정한 권한을 가진 것만 허용
- ex. A나라 성에서 입구에서 검열 = 필터(문지기)
→ 성 입구: A나라 사람만 허용/ 왕의 집: 권한 가진 사람만 허용- 성: 톰캣 / 왕의 집: 스프링 컨테이너 (톰캣의 안에 있는 것 X, 톰캣을 거쳐서 들어감 O)
- 톰캣
- 필터: filter, 필터의 기능을 하는 파일: web.xml
- 스프링 컨테이너
- 필터: Interceptor
- 엄청나게 많은 어노테이션을 가지고 있다. (리플렉션, 컴파일체킹)
- 어노테이션: 컴파일러가 무시하는 것이 아니라 체킹할 수 있게 힌트를 주는 주석 , 주석 + 힌트
- ~> 객체 생성
@Component (클래스를 메모리에 로딩), @Autowired (로딩된 객체를 해당 변수에 집어 넣기)
- ~> 객체 생성
- 리플렉션: 클래스 내부에 어떤 애가 있는지 분석하는 기법
- 특정 클래스 내부에 있는 메서드, 필드, 어노테이션 체킹 후 무엇을 하라고 설정
- 런타임 때 발생(분석)
- 어노테이션: 컴파일러가 무시하는 것이 아니라 체킹할 수 있게 힌트를 주는 주석 , 주석 + 힌트
- MessageConverter를 가지고 있다. 기본값은 현재 Json이다.
- ex. 한국 ↔ 영어 소통 → 어려움 ⇒ 중간언어(XML → JSON) 만듦
중간언어: 모든 사람이 이해하기 쉬운 언어
- 자바 프로그램 -request(요청)→ 파이썬 프로그램
- 자바 Object -messageConvert(Jackson)→ JSON
Jackson: JSON 데이터로 변경해주는 라이브러리
- 자바 Object -messageConvert(Jackson)→ JSON
- ex. 한국 ↔ 영어 소통 → 어려움 ⇒ 중간언어(XML → JSON) 만듦
- BufferedReader와 BufferedWriter를 쉽게 사용할 수 있다.
- bit 단위(0, 1) → 영어 한 문자 ⇒ 8 bit(= 2^8 = 256가지의 문자 전송) / 한글 ⇒ 16 bit
⇒ 8 bit씩 끊어 읽으면 한 문자씩 받을 수 있다 → 8 bit = (논리적으로) 1 byte → 통신의 최소 단위- 유니코드: UTF-8 → 3 byte
- Byte Stream : 1 byte = 8 bit → Java: InputStream으로 읽음 → byte로 읽음 (문자 X)
→ (문자로 변환) char로 캐스팅해서 처리 But, 복잡 ⇒ InputStreamReader(): byte → 문자
→ 문자 하나를 줌 or 배열로 여러 개의 문자 받을 수 있음 But, 배열: 크기가 정해져 있어야 함
⇒ BufferedReader: 가변 길이의 문자를 받을 수 있음_request.getReader() / out /
BufferedWriter: 전송 단위가 문자열로 가변 길이의 데이터를 쓰게 해주는 클래스
→ 대신 Printwriter 사용 : print(), println() 제공- @ResquestBody → BufferedReader 동작
- @ResoponseBody → BufferedWriter 동작
- bit 단위(0, 1) → 영어 한 문자 ⇒ 8 bit(= 2^8 = 256가지의 문자 전송) / 한글 ⇒ 16 bit
- 계속 발전중이다.
JPA란
- Java Persistence API
- 자바에 있는 데이터를 영구히 기록할 수 있는 환경을 제공하는 api
- 데이터를 생성한 프로그램의 실행이 종료돼도 영구히 데이터를 기록할 수 있는 환경을 조성해주는 것
- ex. RAM → 휘발성 데이터 저장 ⇒ 컴퓨터 꺼지면 사라짐
→ 하드디스크에 기록(비휘발성) → 영구적으로 저장
- Persistence(영속성): 데이터를 생성한 프로그램의 실행이 종료되더라도 사라지지 않는 데이터의 특성
= 하나의 데이터가 영구히 기록될 수 있게 해주는 것 → DBMS으로 관리 - API(Application Programming Interface): 인터페이스 ~> 프로그래밍 → 프로그램
- 프로그램을 만들기 위해 제공해주는 인터페이스?
- 인터페이스 vs 프로토콜: 약속을 의미 But, 방식이 다름
→ 인터페이스: 상하관계가 존재하는 약속
/ 프로토콜: 동등한 관계 → www(프로토콜이 만들어서 만들어진 것 = 인터넷)
- ⇒ JPA: 자바 프로그램을 할 때 영구적으로 데이터를 저장하기 위해서 필요한 인터페이스
- 자바에 있는 데이터를 영구히 기록할 수 있는 환경을 제공하는 api
- ORM 기술이다.
- ORM(Object Relational Mapping): Object를 데이터베이스에 연결하는 어떤 방법론
- ex. 건물을 짓는 설계도(2D) → 건물 지음(3D) ⇒ 모델링: 추상적인 개념을 현실 세계에 뽑아 내는 것
- Java -input→ 데이터 ⇒ DML(delete, update, insert)
Java ←output- 데이터 ⇒ SELECT
⇒ 데이터 type이 다름 → class ~> 데이터베이스에 있는 테이블을 모델링 해야 함
= DB 세상에 있는 데이터를 Java 세상에 모델링 한다 - JPA의 인터페이스 규칙을 지켜서 Java에서 클래스 만들어서 실행
→ 데이터베이스의 테이블이 자동으로 생성되게 하는 기법
- 반복적인 CRUD 작업을 생략하게 해준다.
- Java 프로그램 -커넥션 요청→ DB: 신분 확인하고 Session 열어줌 → 연결(connection)
- (쿼리 전송 → 데이터 받고, 받은 데이터 Java Object로 변경) 반복
= CRUD ⇒ 함수로 제공
- 영속성 컨텍스트를 가지고 있다.
- 영속성: 어떤 데이터를 영구적으로 저장하게 해주는 것 → DB에 저장
- 컨텍스트(context): 대상에 대한 모든 정보를 가지고 있는 것/ 어떤 대상이든지 달라붙을 수 있음
- ex. 영숙이의 모든 컨텍스트를 가지고 있다 = 영숙이의 모든 것을 다 알고 있다
- 컨텍스트를 넘겨준다 = 모든 정보를 넘겨준다
- ex. 동물 데이터 만들고 저장하려고 함 → DB에 다이렉트하게 접근해서 저장 X
동물 데이터(Java) → 영속성 컨텍스트(Java가 DB에 저장해야 되는 모든 것들을 알고 있는 것) → DB
⇒ 영속성 컨텍스트 안 데이터와 DB 안 데이터가 동기화 → 다를 경우는 insert X update O - Java가 DB에 저장해야 하는 모든 메타데이터 정보 다룸
⇒ Java ~영속성 컨텍스트~> DB에 데이터 저장 / DB 데이터 ~영속성 컨텍스트~> Java에 데이터 전달
/ 영속성 컨텍스트에서 일어나는 모든 일 자동으로 처리
- DB와 OOP의 불일치성을 해결하기 위한 방법론을 제공한다. (DB는 객체저장 불가능)
- DB: 기본 자료형 O Object X → 두 번의 Select or Join
Java: Object 저장 O ⇒ 서로 모순 - OOP(객체지향)이 아닌 DB 테이블에 맞춘 클래스 만들어야 함
But, ORM → 모델 만들 때 Java가 주도권을 쥐고 있는 모델을 만들 수 있음
⇒ 데이터 insert or select → JPA가 자동으로 맵핑해서 데이터를 넣어줌
class Tema { int id; String name; String year; } class player { int id; String name; int teamId; // (기본 자료형) -> Team team; (Object) } - DB: 기본 자료형 O Object X → 두 번의 Select or Join
- OOP의 관점에서 모델링을 할 수 있게 해준다. (상속, 콤포지션, 연관관계)
- 상속: ex. Engine - Car / 콤포지션: 결합
- DB 만들고 테이블 ~> Car Class 모델링 X, Class 만들고 토대로 자동 생성해서 DB 테이블 만듦 O
Class Engine extends EntityDate { int id; int power; } Class Car extends EntityDate { int id; // PK String name; String color; Engine engine; } Class EntityDate { TimeStamp createDate; TimeStamp updateDate; } - 방언 처리가 용이하여 Migration하기 좋음. 유지보수에도 좋음.
- 스프링 -JPA→ DB
⇒ JPA: MySQL, 오라클, 마리아, … → 정해서 사용 X, 추상화 객체(뭐가 될지 모름)
- 스프링 -JPA→ DB
- 쉽지만 어렵다.
스프링부트 동작원리
소켓(Socket): 운영체제가 가지고 있는 것
ex. A: 소켓 오픈 (포트 5000) → B: ip주소: 5000(포트번호) ⇒ 연결 → 메세지 주고 받는 통신 가능
C: 5000번으로 연결할 수 있는 방법 X
→ 5000번 포트를 연결의 용도로 사용하고 연결되는 순간 새로운 소켓을 만듦(5001번)
→ B가 5000번으로 연결한 후 끊고 5001번(새로운 소켓)으로 통신
= 모든 자원 A와 B가 사용 → 다른 사용자의 요청 X → CPU가 일을 하고 있기 때문
→ 새로운 소켓 만들 때 새로운 스레드(Thread) 만듦 ⇒ 5000: main 스레드 / 5001: 스레드 1
→ C: 5000번에 연결 → 새로운 소켓 랜덤으로 만들어짐 5002: 스레드 2
→ 5000번과 연결 끊기고 5002번으로 연결
⇒ 반복되는 것 = 소켓 통신: 연결이 지속되어 있는 통신
스레드 있으면 시간을 Time Slice해서(= 시간을 쪼개서) 동시에 동작하는 것처럼 보일 수 있음
연결이 계속 되어 있음 → 부하 ↑ → 속도 ↓ But, 통신하는 게 누군지 알 수 있음
⇒ HTTP 통신: 문서를 전달하는 통식 → Stateless 방식: 연결 지속 X 끊어버리는 방식
ex. A: a.txt → C: a.txt → A = A가 a.txt 파일 요청하면 C가 응답하고 끊음
→ 부하 ↓ But, 다시 연결될 때 항상 새로운 사람으로 인식
⇒ 단점 보완 → 웹서버
HTTP 목적: HTML 확장자 가진 문서를 필요한 사람에게 제공해주는 것 = 문서 전달의 목적
(1) 내장 톰켓을 가진다
톰켓을 따로 설치할 필요 없이 바로 실행 가능
소켓 -시스템 콜→ HTTP
시스템 콜: 시스템이 들고 있는 기능을 콜해서 만들어졌다
→ HTTP 기반: 소켓
톰켓 vs 웹서버(아파치)
- 웹서버 - 갑: 을이 필요한 데이터를 가지고 있음
- ex. 내 컴퓨터에 동영상 3개 → 친구들이 보고 싶음 ⇒ 나: 값 / 친구들: 을
- ⇒ HTTP 통신: 을 -request(요청)→ 갑 → 자원의 위치를 요청을 요청해서 필요한 데이터 가져올 수 있음
- request 할 때는 내 컴퓨터의 위치를 알아야함 → IP 주소 알아야 함
- 어떤 동영상 필요한지 정확하게 명시해줘야 함 → URL(location): 자원을 요청하는 주소
- 갑 -response(응답)→ 을
- 요청한 IP 토대로 자기가 누군지 밝히고 그 정보 토대로 그 정보에 응답 ⇒ 갑: 웹서버
- ⇒ 갑: 을의 IP 주소 모름, 알 필요 X, 요청할 때 응답만 하면 됨 = 요청 X → 응답 불가능
- ⇒ HTTP 통신: 단순하게 요청 시에 응답만 해주는 구조
/ 응답: 단순하게 HTML 문서 or 특정 자원(static(정적) 자원) 요청
- 톰켓
- 아파치: .jsp(Java 코드) 이해 X
→ 아파치 + 톰켓: 아파치가 이해하지 X 파일에 대한 요청 → 제어권을 톰켓에게 넘김 - .jsp 파일 안에 있는 모든 자바 코드 컴파일 → 컴파일된 데이터를 .html에 덮어 씌움
- 아파치: .jsp(Java 코드) 이해 X
⇒ 아파치: 요청한 파일을 응답하는 것
/ 톰켓: 요청한 파일 중 자바 코드 요청되면 컴파일해서 html 파일로 번역해서 돌려주는 것
(2) 서블릿 컨테이너
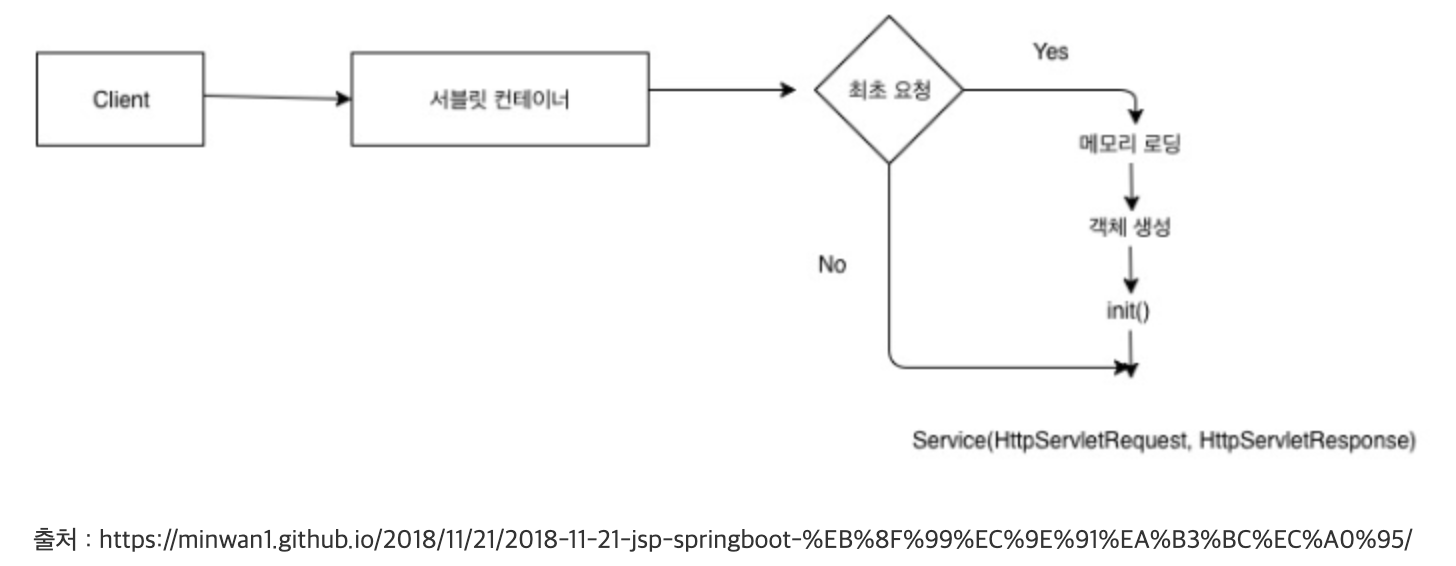
Client 요청 → 서블릿 컨테이너(톰켓)
→ 최초 요청 → 객체 생성
→ 최초 요청 X → 이미 생성된 객체 재사용
- URL(location): 자원에 접근할 때 사용하는 주소 요청 방식 ⇒ 스프링 X
- http://naver.com/a.png
- URI(Identitfier, 식별자): 식별자 ~> 접근하는 방식
- http://naver.com/picture/a
⇒ 특정한 파일 요청을 할 수 X, 요청 시에는 무조건 Java
→ 무조건 아파치는 톰켓에게 제어권을 넘겨줌
- Java 관련 최초 요청(request)
- → 서블릿 컨테이너(톰켓): 서블릿 객체 생성(new)
- init() 호출: 초기화 메서드 ← 기존 스레드 호출
- service() 호출: post/get/put/delete 체크 ← 새로운 스레드 만들어짐: thread 1
- get() 호출
- → 서블릿 컨테이너(톰켓): 서블릿 객체 생성(new)
- 2번째 요청
- → 서블릿 객체 재사용
- init() 실행 X, 새로운 스레드 만들어짐: thread 2
- service() 호출
Class A에 Hell() 메서드 → new A
⇒ heap 공간에 A가 들고 있는 state가 아닌 것들이 뜸 = hello() 메서드가 메모리에 뜸
→ hello() 메서드 호출 → stack 공간 만듦
→ hello() 메서드의 내부 코드를 실행하면서 필요한 메모리 공간으로 사용 = hello() 메서드 stack 공간(독립적)
= 요청 마다 공간이 새로 생김 = 3번 호출 → 3개의 stack 공간
⇒ new → heap에 하나만 / 메서드 호출 → 공유 X 독립적으로 사용
⇒ 서블릿 객체가 1개만 있어도 메서드는 다 따로따로 사용할 수 있음
→ 요청이 오면 thread 만들어져서 요청하고 (반복)
톰켓 기본 설정: thread auto → if thread 20개 → 21번째는 대기
요청 응답 끝나면 thread 종료(종료시점: response)
→ 스레드 1을 메모리에서 날리지 않고(제거하지 않고) 스레드 21번이 스레드 1을 재사용(pooling 기법)
⇒ 서블릿 객체 1개, thread 개수는 컴퓨터 성능마다 다름
- 컴퓨터 성능 업그레이드(thread 50 → 100): scale-up
- 분산 처리(thread 100개 * 컴퓨터 10개): scale-out
(3) web.xml
웹서버에 진입하면 최초에 도는 것
- ServletContext의 초기 파라미터
- 초기 파라미터: 한 번 설정 해두면 어디서든지 동작 가능
- ex. 암구호: 왈라
→ a가 돌아다니다가 암구호 물어봤을 때 제대로 대답하면 정상
- ex. 암구호: 왈라
- 초기 파라미터: 한 번 설정 해두면 어디서든지 동작 가능
- Session의 유효시간 설정
- Session(세션): 인증 ~> 들어오는 것
- a: 3일 동안 체류 가능 → 3일 이후 추방 당해야 함
⇒ 더 있고 싶음 → 세션 초기화
⇒ 문지기에게 내가 누군지 알리고 있을 시간을 늘리려면 문지기에게 가서 말함 - But, 몰래 들어온 사람 → 바로 튕겨나감
- a: 3일 동안 체류 가능 → 3일 이후 추방 당해야 함
- Session(세션): 인증 ~> 들어오는 것
- Servlet/JSP에 대한 정의
- Servlet/JSP 매핑
- 매핑: a가 가려고 하는 목적지(다) → 문지기는 목적지를 찾아서 주소 알려줌
- ⇒ 요청한 자원/로케이션/식별자가 어디라는 것을 알려주고 이동할 수 있게 도와줌
- Mime Type 매핑
- 마임 타입: 들고 올 데이터의 타입 = 어떤 데이터?
- get 방식(select): 데이터를 들고 오지 X
- 가공하는 것 = 파일 변환
- 인코딩: 바이너리 파일 → 텍스트 파일
- 디코딩: 텍스트 파일 → 바이너리 파일
- 텍스트만 보낼 수 있던 SMTP 단점 보완
→ 메세지 내부에 다른 파일을 전송할 수 있도록 하는 전자메일 프로토콜- 인코딩한 파일 → Content-type 필드를 헤더에 담음
~> 전송된 자원의 형식을 명시할 수 있음
- 인코딩한 파일 → Content-type 필드를 헤더에 담음
- 마임 타입: 들고 올 데이터의 타입 = 어떤 데이터?
- Welcome File list
- a가 아무것도 안들고옴(데이터 X 목적지 X) → 문지기가 광장으로 보냄
- Error Pages 처리
- 목적지 모름 = 이상한 주소 → 문지기가 이상한 광장(에러 페이지)로 보냄
- 리스너/필터 설정
- 필터: a가 들어왔을 때 a의 신분을 확인, 총 소지 → 총 소지 X 나라 ⇒ 총 뺏음
- 리스너: 높은 관리자가 술 잘 먹는 사람 필요 → 문지기에게 찾으라고 시킴
→ 새로운 문지기(리스너) 만듦 ⇒ 술 잘 먹는 사람만 확인하는 대리인
- 보안
여기에서 Servlet/JSP 매핑시(web.xml에 직접 매핑 or @WebServlet 어노테이션 사용)에
모든 클래스에 매핑을 적용시키기에는 코드가 너무 복잡해지기 때문에 FrontController 패턴을 이용함
참고 : https://galid1.tistory.com/487
(4) FrontController 패턴
web.xml에 어디로 이동해야 될지 다 정의 X
최초 앞단에서 request 요청을 받아서 필요한 클래스에 넘겨준다.
왜? web.xml에 다 정의하기가 너무 힘듦
→ (최초 요청) url/Java 파일 요청 → 자원에 바로 접근 X 톰켓으로 감
→ 톰켓이 request(요청한 사람 정보-어떤 데이터 요청, 어떤 데이터 들고 왔는지), response(응답할) 객체 만듦
→ 특정 주소 들어오면 frontcontroller가 낚아챔
→ 자원 찾아갈 수 있게 다시 request(내부에서 자원 접근 가능)
⇒ request, response는 요청할 때마다 새로 만들어짐
이때 새로운 요청이 생기기 때문에 request와 response가 새롭게 new 될 수 있음
⇒ RequestDispatcher가 필요
(5) RequestDispatcher
필요한 클래스 요청이 도달했을 때 FrontController에 도착한 request와 response를 그대로 유지시켜준다.
새로운 요청 → 기존 request, response 사라짐
⇒ requestDispatcher → 기존의 request, response 그대로 사용할 수 있음
⇒ 기존 request가 A라는 데이터 가지고 있다면 A라는 데이터 그대로 유지시킬 수 있음
⇒ 새로운 request X, 기존의 request 재사용 O
⇒ 페이지 간 데이터 이동 가능
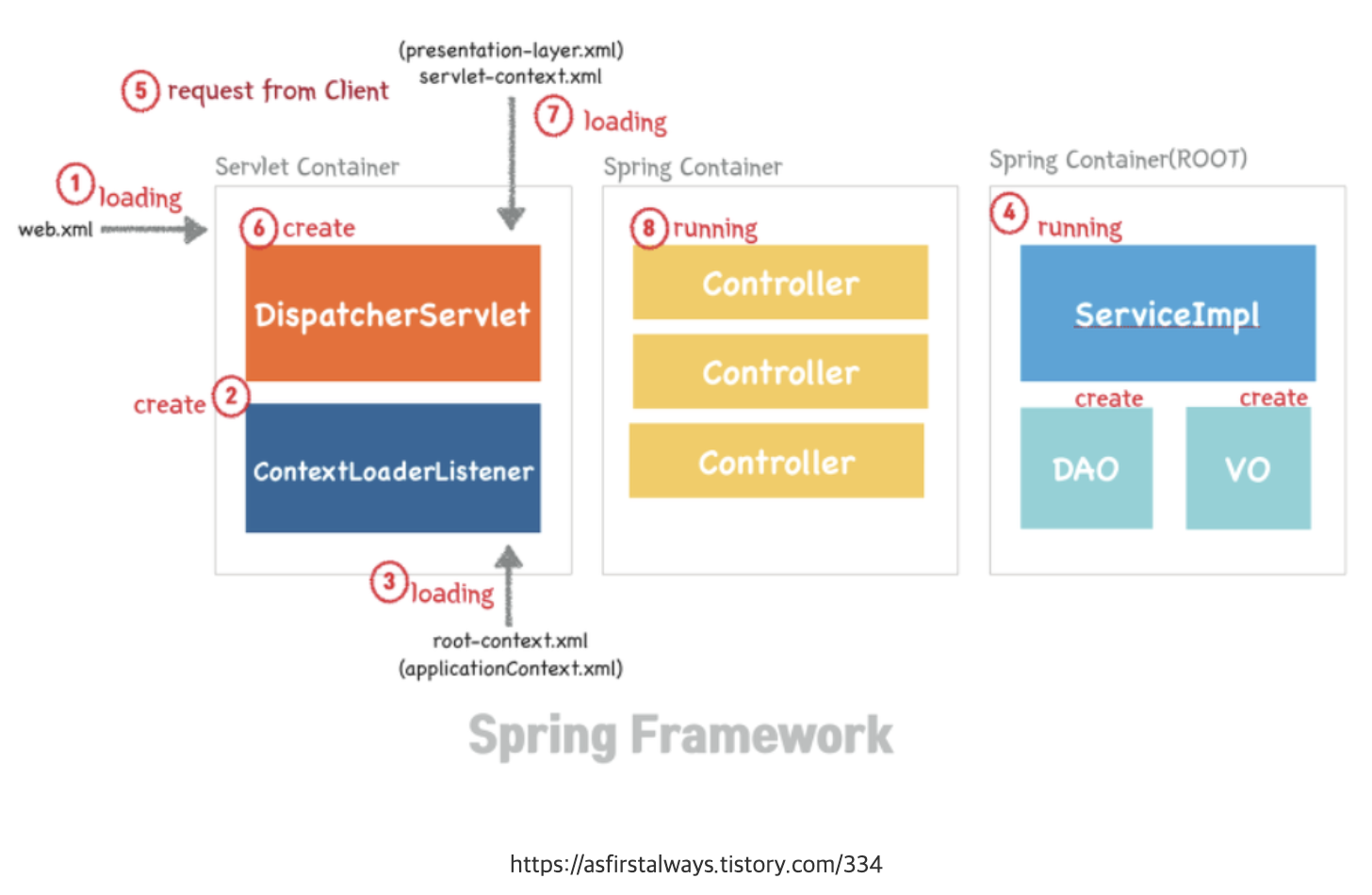
(6) DispatcherServlet(= FrontController 패턴 + RequestDispatcher)
FrontController 패턴을 직접짜거나 RequestDispatcher 직접 구현할 필요 X
→ 왜냐하면 스프링에는 DispatcherServlet이 있기 때문
DispatcherServlet이 자동생성되어 질 때 수 많은 객체가 생성(IoC)된다. 보통 필터들이다.
해당 필터들은 내가 직접 등록할 수 도 있고 기본적으로 필요한 필터들은 자동 등록 되어진다.
(7) 스프링 컨테이너
request → 1. 톰캣: web.xml
2. → ContextLoaderListener
서블릿 만들어짐 → thread(각각 독립적 서로 영향 X ⇒ 충돌 X) 만들어짐
모든 요청하는 애들이 공통적으로 써야하는 것 = DB 커넥션
⇒ ContextLoaderListener: thread가 공통적으로 사용해도 되는 것 띄움
- root-applicationContext
3.→ DispatcherServlet
static → main 메서드(태초에 존재, 공유) / Java 파일 → 객체(생성과 사라짐)
new해서 메모리에 띄워야 하는데 Spring은 IoC = 내가 new 하지 X → DispatcherServlet이 컴포넌트 스캔
~> src 내부에 있는 모든 파일을 스캔해서 new 함
⇒ DispatcherServlet 하는 일
- 컴포넌트 스캔
- 주소 분배(→ Class들 메모리에 떠 있어야 함)
DispatcherServlet에 의해 생성되어지는 수 많은 객체들 ApplicationContext에서 관리 → IoC라고 함
ApplicationContext
IoC: 제어의 역전을 의미
개발자가 직접 new ~> 객체를 생성하게 된다면 해당 객체를 가르키는 레퍼런스 변수를 관리하기 어려움
→ 스프링이 직접 해당 객체를 관리. 이때 우리는 주소를 몰라도 됨, 왜냐하면 필요할 때 DI하면 되기 때문
DI: 의존성 주입
필요한 곳에서 ApplicationContext에 접근하여 필요한 객체를 가져올 수 있음
ApplicationContext는 싱글톤으로 관리 → 어디에서 접근하든 동일한 객체라는 것을 보장
<ApplicationContext의 종류 2가지>
- root-applicationContext
- 최상단
- servlet-applicationContext
- 서블릿만 바라보는 변태 → 모든 정보를 다 두고 있지 X
⇒ 웹과 관련된 어노테이션만 스캔해서 메모리에 띄워 주소 분배
- 서블릿만 바라보는 변태 → 모든 정보를 다 두고 있지 X
a. servlet-applicationContext
- ViewResolver, Interceptor, MultipartResolver 객체를 생성
- 웹과 관련된 어노테이션 Controller, RestController를 스캔
============> 해당 파일은 DispatcherServlet에 의해 실행
b. root-applicationContext
- 해당 어노테이션을 제외한 어노테이션 Service, Repository등을 스캔하고 DB관련 객체를 생성
스캔: 메모리에 로딩한다는 뜻
============> 해당 파일은 ContextLoaderListener에 의해 실행
ContextLoaderListener를 실행해주는 애: web.xml
→ root-applicationContext는 servlet-applicationContext보다 먼저 로드
당연히 servlet-applicationContext에서는 root-applicationContext가 로드한 객체를 참조O 그 반대는 X
→ 생성 시점이 다르기 때문

Bean Factory
필요한 객체를 Bean Factory에 등록할 수도 있음
여기에 등록하면 초기에 메모리에 로드 X 필요할 때 getBean()이라는 메소드 ~> 호출하여 메모리에 로드
이것 또한 IoC이다. 그리고 필요할 때 DI하여 사용할 수 있다.
ApplicationContext와 다른 점
: Bean Factory에 로드되는 객체들은 미리 로드되지 X 필요할 때 호출하여 로드 → lazy-loading이 된다는 점
(8) 요청 주소에 따른 적절한 컨트롤러 요청 (Handler Mapping)
GET요청 => http://localhost:8080/post/1
해당 주소 요청이 오면 적절한 컨트롤러의 함수를 찾아서 실행한다.
참고: https://minwan1.github.io/2017/10/08/2017-10-08-Spring-Container,Servlet-Container/
(9) 응답
html파일/Data 응답 결정해야 함
- html 파일을 응답
- → ViewResolver가 관여 ⇒ 어떤 파일인지에 대한 응답 파일 패턴 만들어줌
- ex. 응답할 데이터: .jsp 파일 → prefix: 경로 + suffix: .jsv 확장자 붙어서
해당 어던 스트링 값에 대한 주소 요청에 대한 파일을 리턴할 수 있는 패턴을 만들어줌 - 해당 파일 리턴: 클라이언트는 웹브라우저 요청(.jsp 파일 이해 X)
→ 톰켓: .jsp파일 → html 파일 return
- Data를 응답 → MessageConverter가 작동, 메시지를 컨버팅할 때 기본전략은 json이다.
- @ResponseBody
- return 값이 객체 -MessageConverter→ json으로 변경
[지금 무료] 스프링부트 개념정리(이론) | 최주호 - 인프런
최주호 | 스프링부트를 공부하며 헷갈리는 개념이 많았던 분 스프링부트에 대해 공부하고 싶었던 모든 분, 스프링부트의 핵심은확실한 개념으로부터! 스프링부트 너무 어려운데 어떻게 시작하
www.inflearn.com
'💻 > Spring | SpringBoot' 카테고리의 다른 글
| Spring Webflux, WebClient (0) | 2025.02.23 |
|---|---|
| gRPC / WebFlux + Netty / WebSocket (0) | 2025.02.23 |
| [Spring Boot 3.x 를 이용한 RESTful Web Services 개발] 섹션 6. RESTful API 설계 가이드 (0) | 2024.04.29 |
| [Spring Boot 3.x 를 이용한 RESTful Web Services 개발] 섹션 5. Java Persistence API 사용 (0) | 2024.04.29 |
| [Spring Boot 3.x 를 이용한 RESTful Web Services 개발] 섹션 4. Spring Boot API 사용 (0) | 2024.04.29 |