
1. MySQL 엔진 아키텍처
MySQL 서버: MySQL 엔진(ex. 사람 머리) + 스토리지 엔진(ex. 손발)
핸들러 API를 만족하면 누구든 스토리지 엔진을 구현해 MySQL 서버에 추가해 사용할 수 있음
1) MYSQL의 전체 구조
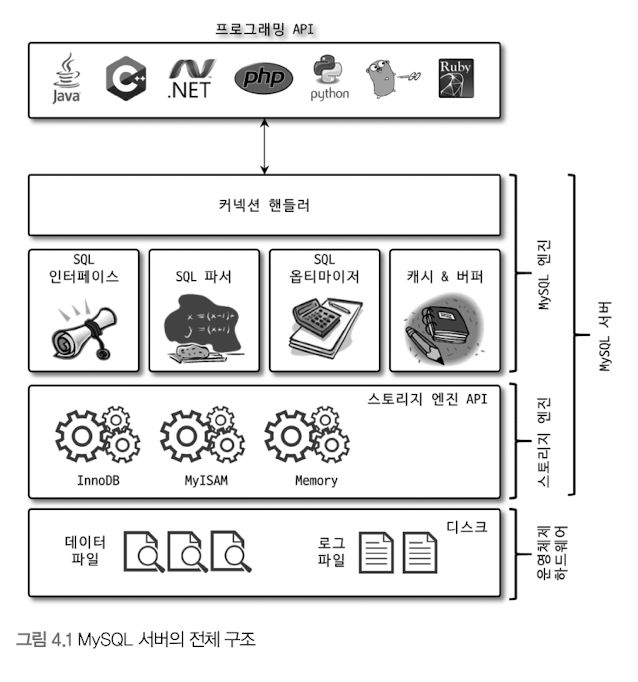
MySQL 엔진
- 커넥션 핸들러:클라이언트로부터의 접속 및 쿼리 요청 처리
- SQL 파서
- 전처리기
- 옵티마이저: 쿼리의 최적화 실행
표준 SQL(ANSI SQL) 문법 지원 -> 타 DBMS와 호환되어 실행 O
스토리지 엔진
- MySQL 엔진(1개): 요청된 SQL 문장 분석 or 최적화
- DBMS의 두뇌에 해당하는 처리/ 1개
- 스토리지 엔진(N개): 실제 데이터 -> 디스크 스토리지에 저장 or 디스크 스토리지부터 데이터 읽어오기
- 여러 개 동시에 사용할 수 있음
- 사용할 스토리지 엔진 지정 -> 해당 테이블의 모든 읽기/변경 작업
- `CREATE TABLE test_table (fd1 INT, fd2 INT) ENGINE=INNODB;
- `test_table`은 InnoDB 스토리지 엔진 사용하도록 정의
- `CREATE TABLE test_table (fd1 INT, fd2 INT) ENGINE=INNODB;
- 성능 향상 -> 키 캐시(MyISAM 스토리지 엔진) or InnoDB 버퍼 풀(InnoDB 스토리지 엔진) 기능 내장
핸들러(Handler) API
핸들러 요청: MySQL 엔진의 쿼리 실행기에서 데이터 쓰기/읽기 -> 각 스토리지 엔진에 쓰기/읽기 요청
-> 사용되는 API: 핸들러 API/ 핸들러 API ~> MySQL 엔진과 데이터를 주고 받음
데이터(레코드) 작업 확인
SHOW GLOBAL STATUS LIKE 'Handler%';2) MYSQL 스레딩 구조

프로세스 기반 X 스레드 기반 O
=> 프그라운드(Foreground) 스레드 / 백그라운드(Background) 스레드
실행 중인 스레드의 목록 확인
SELECT thread_id, name, type, processlist_user, processlist_host
FROM performance_schema, threads ORDER BY type, thread_id;`tread/sql/one_connection` 스레드: 실제 사용자의 요청을 처리하는 포그라운드 스레드
백그라운드 스레드 개수: MySQL 서버의 설정의 내용에 따라 가변적일 수 있음
동일한 이름의 스레드 2개 이상: 여러 스레드가 동일 작업을 병렬로 처리
*스레드 풀 vs. 전통적인 스레드 모델 => 포그라운드 스레드와 커넥션의 관계
전통적인 스레드 모델: 커넥션별로 포그라운드 스레드 하나씩 생성되고 할당 (1:1 관계)
스레드 풀: 하나의 스레드가 여러 개의 커넥션 요청 전담 (-> 4.1.9절 '스레드 풀')
포그라운드 스레드(클라이언트 스레드)
최소한 MySQL 서버에 접속된 클라이언트의 수만큼 존재, 각 클라이언트 사용자가 요청하는 쿼리 문장 처리
클라이언트 사용자가 작업 마치고 커넥션 종료 -> 해당 커넥션 담당하던 스레드는 스레드 캐시(Thread cache)로 되돌아감
이미 스레드 캐시에 일정 개수 이상의 대기 중인 스레드 O -> 스레드 캐시에 넣지 X 스레드 종료
=> 일정 개수의 스레드만 스레드 캐시에 존재
`tread_cache_size` 시스템 변수: 스레드 캐시에 유지할 수 있는 최대 스레드 개수 설정
MySQL의 데이터 버퍼 or 캐시 -> 데이터/ 없는 경우: 직접 디스크의 데이터 or 인덱스 파일로부터 읽어와서 작업 처리
- MyISAM 테이블: 디스크 쓰기 작업까지 포그라운드 스레드가 처리
- InnoDB 테이블: 데이터 버퍼 or 캐시까지만 포그라운드 스레드가 처리
/ 나머지(버퍼로부터 디스크까지 기록): 백그라운드 스레드가 처리
백그라운드 스레드
- 인서트 버퍼(Insert Buffer)를 병합하는 스레드
- 로그를 디스크로 기록하는 스레드(Log thread)
- InnoDB 버퍼 풀의 데이터를 디스크에 기록하는 스레드(Write thread)
- 데이터를 버퍼로 읽어 오는 스레드
- 잠금 or 데드락 모니터링하는 스레드
MySQL 5.5 버전부터: 데이터 쓰기 스레드/데이터 읽기 쓰레드의 개수 2개 이상 지정 O
`innodb_write_io_threads`, `innodb_read_io_threads` 시스템 변수: 스레드 개수 설정
InnoDB에서도 데이터 읽는 작업: 주로 클라이언트 스레드에서 처리
-> 읽기 스레드 많이 설정할 필요 X But, 쓰기 스레드: 많은 작업 백그라운드로 처리
-> 일반적인 내장 디스크 사용할 때 2~4
/ DAS or SAN 같은 스토리지 사용할 때는 디스크를 최적으로 사용할 수 있을 만큼 충분히 설정하는 것이 좋음
3) 메모리 할당 및 사용 구조
MySQL에서 사용되는 메모리 공간: 글로벌 메모리 영역 / 로컬 메모리 영역
- 모든 메모리 공간은 MySQL 서버가 시작되면서 운영체제로부터 할당
- 요청된 메모리 공간 100% or 그 공간만큼 예약, 필요할 때 조금씩 할당해주는 경우
- 할당 방식 복잡, 서버가 사용하는 정확한 메모리 양 측정 어려움
- -> MySQL 시스템 변수로 설정해 둔 만큼 운영체제로부터 메모리를 할당받는다고 생각
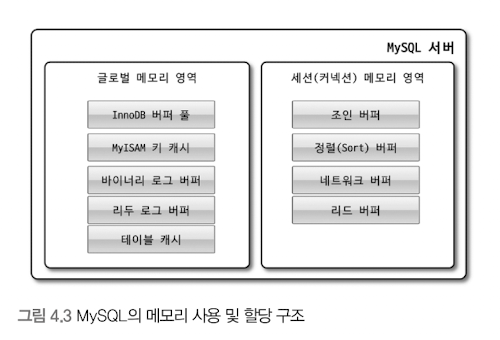
글로벌 메모리 영역
클라이언트 스레드 수와 무관하게 하나의 메모리 공간만 할당
-> 필요에 따라 2개 이상의 메모리 공간 할당받을 수 있음
생성된 글로벌 영역이 N개라고 해도 모든 스레드에 의해 공유
테이블 캐시/ InnoDB 버퍼 풀/ InnoDB 어댑티브 해시 인덱스/ InnoDB 리두 로그 버퍼
로컬 메모리 영역(= 세션 메모리 영역)
- 클라이언트 스레드가 사용하는 메모리 공간 => 클라이언트 메모리 영역
- 클라이언트) MySQL 서버 접속 -> 서버) 클라이언트 커넥션으로부터의 요청 처리 위해 스레드를 하나씩 할당
- 클라이언트와 MySQL 서버와의 커넥션: 세션 => 세션 메모리 영역
MySQL 서버상에 존재하는 클라이언트 스레드가 쿼리를 처리하는 데 사용하는 메모리 영역
각 클라이언트 스레드별로 독립적으로 할당, 공유 X
일반적으로 메모리 영역 크기 신경 쓰지 않고 설정(vs. 글로벌 메모리 영역: 주의)
-> 최악의 경우: MySQL 서버가 메모리 부족으로 멈출 수 있으므로 적절한 메모리 공간 설정 필요
- 각 쿼리의 용도별로 필요할 때만 공간 할당, 필요 X -> 할당 하지 않을 수 있음
- ex. 정렬 버퍼 or 조인 버퍼
- 커넥션이 열려 있는 도안 계속 할당된 상태로 남아 있는 공간
- ex. 커넥션 버퍼, 결과 버퍼
- 쿼리를 실행하는 순간에만 할당했다가 다시 해제하는 공간
- ex. 정렬 버퍼 or 조인 버퍼
정렬 버퍼(Sorted buffer)/ 조인 버퍼/ 바이너리 로그 캐시/ 네트워크 버퍼
4) 플러그인 스토리지 엔진 모델

대부분의 작업 -> MySQL 엔진에서 처리, 마지막 데이터 읽기/쓰기 -> 스토리지 엔진에서 처리
IF. 사용자) 새로운 용도의 스토리지 엔진을 만들어도 DBMS의 전체 기능 X 일부분의 기능만 수행하는 엔진 작성 O
데이터 읽기/쓰기 작업: 대부분 1건의 레코드 단위
ex. 특정 인덱스의 레코드 1건 읽기 or 마지막 읽은 레코드의 다음/이전 레코드 읽기
<핸들러(Handler) = 핸들러 객체>
- MySQL 서버의 소스코드로부터 넘어온 표현
- 어떤 기능을 호출하기 위해 사용하는 운전대와 같은 역할을 하는 객체
- ex. 사람이 핸들(운전대)을 이용해 자동차 운전
- MySQL 엔진 - 사람 역할 / 각 스토리지 엔진 - 자동차 역할
=> MySQL 엔진이 스토리지 엔진을 조절(데이터 읽기/저장 명령)하기 위해 핸들러 사용
`Handler_`로 시작하는 상태 변수: MySQL 엔진이 각 스토리지 엔진에게 보낸 명령의 횟수를 의미하는 변수
`GROUP BY` or `ORDER BY` 등 복잡한 처리: 스토리지 엔진 X MySQL의 처리 영역인 쿼리 실행기에서 처리
하나의 쿼리 작업 -> 여러 하위 작업으로 나뉘어짐
각 하위 작업이 MySQL 엔진 영역 or 스토리지 엔진 영역 처리 구분할 줄 알아야 함
// MySQL 서버(mysqld)에서 지원되는 스토리지 엔진
SHOW ENGINES;
`Support` 칼럼에 표시될 수 있는 값
- YES: 현재 MySQL 서버에 포함 O/ 사용 가능으로 활성화된 상태
- DEFAULT: 'YES'와 동일한 상태/ 필수 스토리지 엔진(없으면 MySQL 시작되지 않을 수도 있음)
- NO: 현재 MySQL 서버에 포함 X
- DISABLED: 현재 MySQL 서버에 포함 O/ 파라미터에 의해 비활성화된 상태
MySQL 서버에 포함 X 스토리지 엔진(`Support` = NO) 사용
-> MySQL 서버를 다시 빌드(컴파일)해야 함 => 플러그인 형태로 빌드된 스토리지 엔진 라이브러리
스토리지 엔진, 인증 및 전문 검색용 파서와 같은 플러그인 (설치 O) 확인
SHOW PLUGINS;
+ 인증 or 전문 검색 파서 or 쿼리 재작성 플러그인, 비밀번호 검증과 커넥션 제어 등 관련된 플러그인
/ MySQL 서버의 기능을 커스텀하게 확장할 수 있게 플러그인 API -> 메뉴얼에 공개
=> 기존 MySQL 서버에서 제공하던 기능 확장 or 완전히 새로운 기능을 플러그인 이용해 구현할 수 있음
5) 컴포넌트
8.0 버전부터: 기존 플러그인 아키텍처 대처 -> 컴포넌트 아키텍처 지원
<MySQL 서버 플러그인 단점>
- 오직 MySQL 서버와 인터페이스할 수 있고, 플러그인끼리 통신 X
- MySQL 서버의 변수나 함수 직접 호출 -> 안전 X (캡슐화 X)
- 상호 의존 관계 설정 X -> 초기화 어려움
비밀번호 검증 기능
5.7 버전까지: 플러그인 형태로 제공 / 8.0 버전부터: 컴포넌트로 개선
// validate_password 컴포넌트 설치
INSTALL COMPONENT 'file://component_validate_password';
// 설치된 컴포넌트 확인
SELECT * FROM mysql.component;5) 쿼리 실행 구조
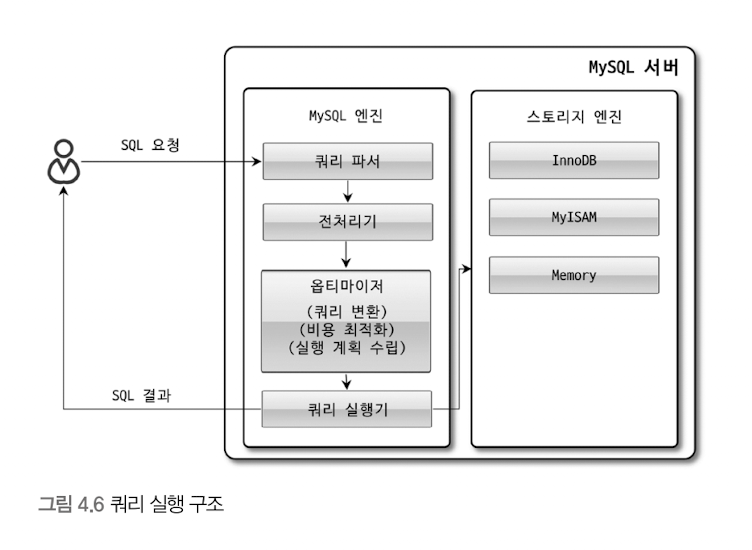
쿼리 파서
사용자 요청으로 들어온 쿼리 문장 -> 토큰으로 분리 => 트리 형태의 구조로 만들어내는 과정
MySQL이 인식할 수 있는 최소 단위의 어휘/기호
=> 쿼리 문장의 기본 문법 오류 발견, 사용자에게 오류 메시지 전달
전처리기
파서 과정에서 만들어진 파서 트리 기반으로 쿼리 문장에 구조적인 문제점이 있는지 확인
각 토큰 -> 테이블 이름 or 칼럼 이름 or 내장 함수와 같은 개체를 매핑 => 해당 객체의 존재 여부, 객체의 접근 권한 등 확인하는 과정
=> 실제 존재 X or 권한상 사용할 수 없는 개체의 토큰 발견
옵티마이저
사용자의 요청으로 들어온 쿼리 문장 -> 저렴한 비용으로 가장 빠르게 처리할지 결정하는 역할
실행 엔진
옵티마이저 - 두뇌 or 경영진 / 실행 엔진, 핸들러 - 손과 발 or 중간 관리자, 실무자
가정: 옵티마이저가 `GROUP BY`를 처리하기 위해 임시 테이블 사용
- 실행 엔진) 임시 테이블 만들라고 핸들러에게 요청
- 실행 엔진) `WHERE` 절에 일치하는 레코드를 읽어오라고 핸들러에게 요청
- 읽어온 레코드들을 1번에서 준비한 임시 테이블로 저장하라고 핸들러에게 요청
- 데이터가 준비된 임시 테이블에서 필요한 방식으로 데이터를 읽어 오라고 핸들러에게 다시 요청
- 실행 엔진) 사용자 or 다른 모듈로 넘김
=> 만들어진 계획대로 각 핸들러에게 요청해서 받은 결과 -> 또 다른 핸들러 요청의 입력으로 연결하는 역할
핸들러(스토리지 엔진)
- MySQL 서버의 가장 밑단에서 MySQL 실행 엔진의 요청 -> 데이터를 디스크에 저장, 디스크로부터 읽어 오는 역할 담당
- 스토리지 엔진을 의미
- MySQL 테이블 조작하는 경우: MyISAM 스토리지 엔진이 핸들러
- InnoDB 테이블 조작하는 경우: InnoDB 스토리지 엔진이 핸들
7) 쿼리 캐시(Query Cache)
빠른 응답을 필요로 하는 웹 기반의 응용 프로그램에서 중요한 역할
- SQL의 실행 결과 -> 메모리에 캐시
/ 동일 SQL 쿼리 실행 -> 테이블 읽지 않고 즉시 결과 반환 => 매우 빠른 성능 - 테이블의 데이터 변경 -> 캐시에 저장된 결과 중에서 변경된 테이블과 관련된 것들 모두 삭제(Invalidate)
=> 동시 처리 성능 저하 유발
=> 데이터 변경 거의 X 읽기만 하는 서비스에서 좋은 기능
MySQL 서버가 발전하면서 성능이 개선되는 과정에서 쿼리 캐시는 계속된 동시 처리 성능 저하, 많은 버그의 원인
MySQL 8.0 버전부터: MySQL 서버의 기능에서 완전히 제거, 관련된 시스템 변수 제거
8) 스레드 풀(Thread Pool)
엔터프라이즈 에디션: 스레드 풀 기능 제공 O / 커뮤니티 에디션: X
- 엔터프라이즈: MySQL 서버 프로그램에 내장
- Percona Server: 플러그인 형태로 작동하게 구현돼 있음
- 스레드 풀 플러그인 라이브러리(`thread_pool.so 파일`)를 설치(`INSTALL PLUGIN)
=> 엔터프라이즈 에디션에 포함된 스레드 풀 대신 Percona Server에서 제공하는 스레드 풀 기능
목적: 내부적으로 사용자의 요청을 처리하는 스레드 개수 ↓
-> 동시에 처리되는 요청이 많아도 서버의 CPU가 제한된 개수의 스레드 처리에만 집중할 수 있게 함 => 서버의 자원 소모 ↓
Q. 스레드 풀만 설치하면 성능 2배?
A. (X) 실제 서비스에서 눈에 띄는 성능 향상 보여준 경우 드물다
스레드 풀: 동시에 실행 중인 스레드들 -> CPU가 최대한 잘 처리해낼 수 있는 수준으로 줄여서 빨리 처리하게 하는 기능
-> 스케줄링 과정에서 CPU 시간을 제대로 확보 X -> 쿼리 처리가 더 느려지는 사례도 발생할 수 O
제한된 수의 스레드만으로 CPU가 처리하도록 적절히 유도
-> CPU의 프로세서 친화도(Processor affinity) ↑, OS 입장에서 불필요한 컨텍스트 스위치(Context switch) ↓
=> 오버헤드 ↓
- CPU 코어의 개수만큼 스레드 그룹 생성
- `thread_pool_size` 시스템 변수: 스레드 그룹 개수 변경
- 일반적으로 CPU 코어의 개수와 맞추는 것이 CPU 프로세서 친화도를 높이는 데 좋음
- 처리해야 할 요청 O -> 스레드 풀로 처리 이관
- IF. 이미 스레드 풀이 처리 중인 작업 O
-> `thread_pool_oversubscribe` 시스템 변수(기본값: 3)에 설정된 개수만큼 추가로 더 받아들여서 처리- 값이 너무 ↑ -> 스케줄링해야 할 스레드 ↑ => 스레드 풀 비효율적으로 작동할 수도 있음
- IF. 이미 스레드 풀이 처리 중인 작업 O
- 스레드 그룹의 모든 스레드가 일을 처리 -> 스레드 풀
(해당 스레드 그룹에 새로운 작업 스레드(Worker thread) 추가 vs. 기존 작업 스레드가 처리를 완료할 때까지 기다림) 여부 판단- 타이머 스레드: 주기적으로 스레드 그룹의 상태 체크 -> `thread_pool_stall_limit` 시스템 변수에 정의된 밀리초만큼 작업 스레드가 지금 처리 중인 작업 끝내지 X -> 새로운 스레드 생성해서 스레드 그룹에 추가
- 전체 스레드 풀에 있는 스레드 개수 < `thread_pool_max_threads` 시스템 변수에 설정된 개수
- 모든 스레드 그룹의 스레드가 각자 작업을 처리하고 있는 상태에서 새로운 요청이 들어와도 스레드 풀은 `thread_pool_stall_limit` 시간 동안 기다려야만 새로 들어온 요청 처리 O
- => 응답 시간에 민감한 서비스: `thread_pool_stall_limit` 시스템 변수 적절히 낮춰서 설정해야 함
- But, 0으로 가까운 값으로 설정 권장 X -> 스레드 풀을 사용하지 않는 편이 나음
- 타이머 스레드: 주기적으로 스레드 그룹의 상태 체크 -> `thread_pool_stall_limit` 시스템 변수에 정의된 밀리초만큼 작업 스레드가 지금 처리 중인 작업 끝내지 X -> 새로운 스레드 생성해서 스레드 그룹에 추가
- 선순위 큐, 후순위 큐 -> 특정 트랜잭션 or 쿼리를 우선적으로 처리할 수 있는 기능 제공
- 먼저 시작된 트랜잭션 내에 속한 SQL 빨리 처리 -> 해당 트랜잭션이 가지고 있던 잠금이 빨리 해제, 잠금 경합 ↓
=> 전체적인 처리 성능 향상
- 먼저 시작된 트랜잭션 내에 속한 SQL 빨리 처리 -> 해당 트랜잭션이 가지고 있던 잠금이 빨리 해제, 잠금 경합 ↓

9) 트랜잭션 지원 메타데이터
데이터 딕셔너리 or 메타데이터: 데이터베이스 서버에서 테이블의 구조 정보와 스토어드 프로그램 등의 정보
5.7 버전까지: 테이블의 구조 -> FRM 파일에 저장, 일부 스토어드 포그램 또한 파일(*.TRN, *.TRG, *.PAR, ...) 기반으로 관리
But, 파일 기반의 메타데이터: 생성/변경 작업 -> 트랜잭션 지원 X => 서버 비정상적으로 종료 -> 일관 X 상태로 남는 문제
= 데이터베이스나 테이블이 깨졌다
8.0 버전부터: (해결) 테이블의 구조 정보 or 스토어드 프로그램의 코드 관련 정보 -> 모두 InnoDB의 테이블에 저장
- 시스템 테이블: MySQL 서버가 작동하는 데 기본적으로 필요한 테이블
- ex. 사용자 인증과 권한에 관련된 테이블
- InnoDB 스토리지 엔진 사용/ 시스템 테이블, 데이터 딕셔너리 정보 -> mysql DB에 저장
/ mysql DB -> `mysql.ibd`라는 이름의 테이블스페이스에 저장
=> MySQL 서버의 데이터 디렉터리에 존재하는 `mysql.ibd` 파일은 다른 *.ibd 파일과 함께 특별히 주의해야 함
참고
mysql DB에 데이터 딕셔너리를 저장하는 테이블이 저장
But, 실제 mysql DB에서 테이블의 목록 살펴보면 실제 테이블의 구조가 저장된 테이블 보이지 X 실제 존재 O
-> 데이터 딕셔너리 테이블의 데이터를 사용자가 임의로 수정하지 X
=> 데이터 딕셔너리 정보를 `information_schema DB`의 `TABELS`와 `COLUMNS` 등과 같은 뷰 ~> 조회 O
mysql DB에서 `tables`라는 이름의 테이블에 대해 `SELECT` 실행 -> '테이블 없음 X 접근 거절됨 O
- 스키마 변경 작업 중간에 MySQL 서버가 비정상적으로 종료돼도 스키마 변경 완전한 성공/완전한 실패
- InnoDB 스토리지 엔진 사용하는 테이블: 메타 정보 -> InnoDB 테이블 기반의 딕셔너리에 저장
/ MyISAM or CSV 등과 같은 스토리지 엔진의 메타 정보 => 저장할 공간 필요- (InnoDB 스토리지 엔진 이외) SDI(Serialized Dictionary Information) 파일 사용
SDI: 직렬화(Serialized)를 위한 포맷 - SDI 포맷의 *.sdi 파일 존재/ *.FRM 파일과 동일한 역할
- InnoDB 테이블들의 구조도 SDI 파일로 변환할 수 있음
- (InnoDB 스토리지 엔진 이외) SDI(Serialized Dictionary Information) 파일 사용
- `ibd2sdi` 유틸리티: InnoDB 테이블스페이스에서 스키마 정보 추출
- `SHOW TABLES`로 확인할 수 X `mysql.tables` 딕셔너리 데이터를 위한 테이블 구조도 볼 수 있음
linux> ibd2sdi mysql_data_dir/mysql.ibd > mysql_schema.json
linux> cat mysql schema.json출처
GitHub - wikibook/realmysql80: 《Real MySQL 8.0》 예제 파일
《Real MySQL 8.0》 예제 파일. Contribute to wikibook/realmysql80 development by creating an account on GitHub.
github.com
'📓 > 데이터베이스' 카테고리의 다른 글
| [Real MySQL 8.0 1] 06 데이터 압축 (0) | 2025.01.27 |
|---|---|
| [Real MySQL 8.0 1] 05 트랜잭션과 잠금 (0) | 2025.01.24 |
| [Real MySQL 8.0 1] 04 아키텍처 - 3. MyISAM 스토리지 엔진 아키텍처 / 4. MySQL 로그 파일 (0) | 2025.01.24 |
| [Real MySQL 8.0 1] 04 아키텍처 - 2. InnoDB 스토리지 엔진 아키텍처 (0) | 2025.01.24 |
| [Real MySQL 8.0 1] 03 사용자 및 권한 (0) | 2025.01.23 |