
1. 페이지 압축(Transparent Page Compression)
- MySQL 서버가 디스크에 저장하는 시점에 데이터 페이지 압축돼 저장
/ MySQL 서버가 디스크에서 데이터 페이지를 읽어올 때 압축 해제 - 버퍼 풀에 데이터 페이지 한 번 적재 -> InnoDB 스토러지 엔진: 압축이 해제된 상태로만 데이터 페이지 관리
- 서버의 내부 코드에서는 압축 여부 관계 X 투명(Tranparent)하게 작동
- (-) 16KB 데이터 페이지를 압축한 결과가 용량이 얼마나 될지 예측 불가능
- 적어도 하나의 테이블은 동일한 크기의 페이지(블록)으로 통일돼야 함
운영체제별로 특정 버전의 파일 시스템에서만 지원되는 펀치 홀(Punch hole)이라는 기능 사용
운영체계(파일 시스템)의 블록 사이즈: 512바이트 -> 페이지 압축이 작동하는 방식
특정 테이블에 대해 16KB 크기의 페이지를 유지하면서도 압축된 다양한 크기의 페이지 -> 디스크에 저장, 압축된 만큼의 공간 절약
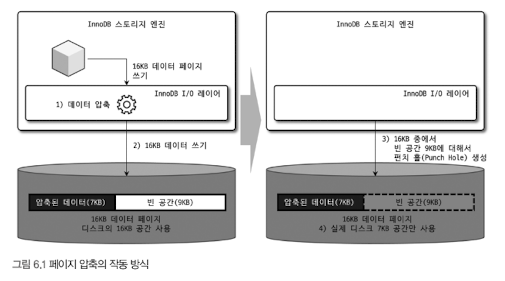
- 16KB 페이지를 압축(압축 결과: 7KB로 가정)
- 서버는 디스크에 압축된 결과 7KB를 기록(압축 데이터 7KB에 9KB의 빈 데이터를 기록)
- 디스크에 데이터 기록한 후, 7KB 이후의 공간 9KB에 대해 펀치 홀 생성
- 파일 시스템은 7KB만 남기고 나머지 디스크의 9KB 공간은 다시 운영체제로 반납
펀치 홀
- (-) 운영체제, 하드웨어 자체에서도 해당 기능을 지원해야 사용 가능함
- (-) 아직 파일 시스템 관련 명령어(유틸리티)가 펀치 홀 지원 X
데이터 파일은 해당 서버에만 머무는 것 X
백업했다가 복구하는 과정에서 데이터 파일 복사 과정 실행, 그 외에도 많은 파일 관련 유틸리티 사용
ex. 펀치 홀 적용 -> 실제 데이터 파일의 크기 1GB여도 복사 명령(cp) or XtraBackup 같은 툴이 파일 복사
-> 펀치 홀 다시 채워짐 => 데이터 파일의 크기는 원본 크기인 10GB 될 수도 있음
=> 실제 페이지 압축 많이 사용 X
페이지 압축 이용 -> 테이블 생성 or 변경할 때 `COMPRESSION` 옵션 설정
-- 테이블 생성
CREATE TABLE t1 (c1 INT) COMPRESSION="zlib";
-- 테이블 변경
ALTER TABLE t1 COMPRESSION="zlib";
OPTIMIZE TABLE t1;2. 테이블 압축
- 운영체제/하드웨어 제약 X 사용할 수 있음 -> 활용도 ↑
- (+) 디스크의 데이터 파일 크기 줄일 수 있음
- (-) 버퍼 풀 공간 활용률 ↓ / 쿼리 처리 성능 ↓ / 빈번한 데이터 변경 -> 압축률 ↓
1) 압축 테이블 생성
전제 조건: 압축을 사용하려는 테이블이 별도의 테이블 스페이스를 사용해야 함
-> `innodb_file_per_table` 시스템 변수가 ON으로 설정된 상태에서 테이블 생성돼야 함
테이블 생성할 때 `ROW_FORMAT=COMPRESSED` 옵션 명시해야 함
`KEY_BLOCK_SIZE` 옵션: 압축된 페이지의 타깃 크기(목표 크기) 명시/ 2n(n 값 >= 2)으로만 설정할 수 있음
ex. InnoDB 스토리지 엔진의 페이지 크기(`innodb_page_size`)가 16KB -> `KEY_BLOCK_SIZE=4KB or 8KB`
페이지 크기가 32KB or 64KB -> 테이블 압축 적용 X
SET GLOBAL innodb_file_per_table=ON;
-- ROW_FORMAT 옵션과 KEY_BLOCK_SIZE 옵션을 모두 명시
CREATE TABLE compressed_table (
c1 INT PRIMARY KEY
)
ROW_FORMAT=COMPRESSED
KEY_BLOCK_SIZE=8;
-- KEY_BLOCK_SIZE 옵션만 명시
CREATE TABLE compressed_table (
c1 INT PRIMARY KEY
)
KEY_BLOCK_SIZE=8;`ROW_FORMAT` 옵션 생략 -> 자동으로 `ROW_FORMAT=COMPRESSED` 옵션 추가돼 생성
`KEY_BLOCK_SIZE`에 명시된 옵션값: KB 단위 설정 -> 앞의 테이블의 `KEY_BLOCK_SIZE`는 8KB 의미
참고
`innodb_file_per_table` 시스템 변수가 0인 상태에서 제너럴 테이블스페이스(General Tablespace)에 생성되는 테이블도 테이블 압축 사용할 수 잇음 But, `FILE_BLOCK_SIZE`에 의해 압축 사용할 수도 있고 그러지 못할 수도 있음
`KEY_BLOCK_SIZE` 옵션: 압축된 페이지가 저장될 페이지의 크기 지정
ex. 현재 InnoDB 스토리지 엔진의 데이터 페이지(블록) 크기: 16KB, `KEY_BLOCK_SIZE=8`
데이터 페이지를 압축한 용량이 얼마가 될지 알 수 없는데, 어떻게 `KEY_BLOCK_SIZE` 테이블을 생성할 때 설정할 수 있을까?
InnoDB 스토리지 엔진이 압축을 적용하는 방법
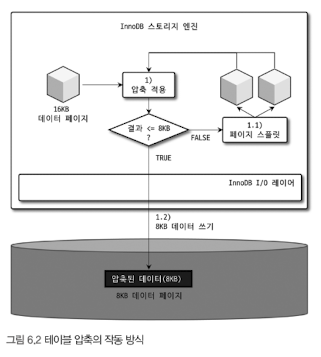
- 16KB의 데이터 페이지를 압축
- 압축된 결과 <= 8KB: 그대로 디스크에 저장(압축 완료)
- 압축된 결과 > 8KB: 원본 페이지를 스플릿(split) -> 2개의 페이지에 8KB씩 저장
- 나뉜 페이지 각각에 대해 1번 단계 반복 실행
InnoDB I/O 레이어에서는 아무런 역할 하지 X
가장 중요한 것: 원본 데이터 페이지의 압축 결과과 목표 크기(`KEY_BLOCK_SIZE`)보다 작거나 같을 때까지 반복해서 페이지 스플릿
-> 목표 크기 잘못 설정되면 처리 성능 급격히 떨어질 수 있음
2) KEY_BLOCK_SIZE 결정
압축된 결과가 어느 정도가 될지 예측해 `KEY_BLOCK_SIZE`를 결정해야 함
-> 테이블 압축을 적용하기 전 `KEY_BLOCK_SIZE`를 4KB or 8KB로 테이블 생성해 샘플 데이터를 저장해보고 적절한지 판단
샘플 데이터 ↑ -> 더 정확한 테스트 할 수 있음 => 최소한 테이블의 데이터 페이지 10개 정도 생성되도록 테스트 데이터 `INSERT`
`KEY_BLOCK_SIZE` 선택하는 예시
UES employees;
-- 동일한 구조로 테이블 압축을 사용하는 예제 테이블 생성
CREATE TABLE employees_comp4k (
emp_no int NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
gender enum('M', 'F') NOT NULL,
hire_date date NOT NULL,
PRIMARY KEY (emp_no),
KEY ix_firstname (first_name),
KEY ix_hiredate (hire_date)
) ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=4;
-- 테스트 실행 전 innodb_cmp_per_index_enabled 시스템 변수 ON으로 변경해야
-- 인덱스별로 압축 실행 횟수와 성공 횟수 기록
SET GLOBAL innodb_cmp_per_index_enabled=ON;
-- employees 테이블의 데이터를 그대로 압축 테스트 테이블로 저장
INSERT INTO employees_comp4k SELECT * FROM employees;
-- 인덱스별로 압축 횟수, 성공 횟수, 압축 실패율 조회
SELECT table_name, index_name, compress_ops, compress_ops_ok,
(compress_ops-compress)ops_ok/compress_ops * 100 as compression_failure_pct
FROM information_schema.INNODB_CMP_PER_INDEX;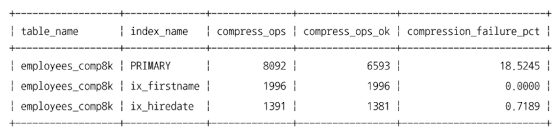
압축된 테이블의 PRIMARY 키는 전ㅊ네 18653번 압축 실행, 13478번 성공
= 5175(18653 - 13478)번 압축
-> 압축 결과 4KB 초과 -> 데이터 페이지를 스플릿해서 다시 압축 실행
PRIMARY 압축 실패율: 27.67%, 나머지 2개 인덱스도 압축 실패율 상대적으로 높음
(3~5% 미만으로 유지할 수 있게 `KEY_BLOCK_SIZE` 선택하는 것이 좋음)
`KEY_BLOCK_SIZE=8KB` 설정 후 동일 테스트

PRIMARY 압축 실패율이 꽤 높게 나타남
=> 압축 적용하면 압축 실패율 ↑
-> InnoDB 버퍼 풀에서 디스크로 기록되기 전 압축하는 과정이 꽤 오랜 시간 걸릴 것이라고 예측할 수 있음
=> 성능에 민감한 서비스 -> 압축을 적용하지 않는 것이 좋음
=> 압축한 결과 4KB, 8KB 거의 차이 X
-> 굳이 압축 선택한다면 압축 실패율 낮으면서 효율 상대적으로 높은 8KB 선택하는 것이 효율적
(압축 실패율 ↑ != 실제 디스크 데이터 파일 줄어들지 않음) == 실제 디스크 데이터 파일 줄어듦
ex. `INSERT`만 되는 로그 테이블의 경우 한 번 `INSERT`되면 이후에 다시 변경 X
-> 한 번 정도는 압축 시도가 실패해 페이지 스플릿 후 재압축해도 전체적으로 데이터 파일의 크기가 큰 폭으로 줄어들면 손해 X
압축 실패율 높지 않아도 테이블의 데이터가 매우 빈번하게 조회되고 변경 -> 압축 X
zlib 이용해 압축 실행/ 압축 알고리즘: ↑ CPU 자원 소모
3) 압축된 페이지의 버퍼 풀 적재 및 사용
InnoDB 스토리지 엔진: 압축된 테이블의 데이터 페이지 -> 버퍼 풀에 적재
=> (압축된 상태/ 압축 해제된 상태) 2개 버전 관리
=> LRU 리스트: 디스크에서 읽은 상태 그대로 데이터 페이지 목록 관리 / Unzip_LRU 리스트: 압축된 페이지들의 압축 해제 버전
LRU 리스트
- 압축 적용 X 테이블의 데이터 페이지
- 압축 적용 O 테이블의 압축된 데이터 페이지
Unzip_LRU 리스트
압축이 적용되지 않은 테이블의 데이터 페이지 가지지 X
압축이 적용된 테이블에서 읽은 데이터 페이지만 관리
압축을 해제한 상태의 데이터 페이지 목록 관리
- 단점
- (-) 압축된 테이블 -> 버퍼 풀의 공간을 이중으로 사용 => 메모리 낭비
- (-) 압축된 페이지에서 데이터 읽거나 변경하기 위해서는 압축 해제해야 함
- 압축/압축 해제 작업: CPU 상대적으로 ↑ 소모하는 작업
- 단점 보완: Unzip_LRU 리스트를 별도로 관리하고 있다가 MySQL 서버로 유입되는 요청 패턴에 따라 적절히(Adaptive) 처리 수
- InnoDB 버퍼 풀의 공간이 필요한 경우: LRU 리스트에서 원본 데이터 페이지(압축된 형태)는 유지,
Unzip_LRU 리스텡서 압축 해제된 버전 제거 -> 버퍼 풀의 공간 확보 - 압축된 데이터 페이지가 자주 사용되는 경우: Unzip_LRU 리스트에 압축 해제된 페이지 계속 유지, 압축/압축 해제 작업 최소화
- 압축된 데이터 페이지 사용 X -> LRU 리스트에서 제거된 경우: Unzip_LRU 리스트에서도 함께 제거됨
- InnoDB 버퍼 풀의 공간이 필요한 경우: LRU 리스트에서 원본 데이터 페이지(압축된 형태)는 유지,
버퍼 풀에서 압축 해제된 버전의 데이터 페이지를 적절한 수준으로 유지 -> 어댑티브(적응적인) 알고리즘 사용
- CPU 사용량 ↑ 서버: 가능하면 압축/압축 해제 피하기 위해 Unzip_LRU 비율 높여서 유지
- Disk IO 사용량 ↑ 서버: 가능하면 Unzip_LRU 리스트 비율 낮춰서 InnoDB 버퍼 풀의 공간 더 확보
4) 테이블 압축 관련 설정
연관된 시스템 변수 -> 압축 실패율 낮추기 위해 필요한 튜닝 포인트 제공
- `innodb_cmp_per_index_enabled`: 테이블 압축이 사용된 테이블의 모든 인덱스별로 압축 성공, 압축 실행 횟수 수집하도록 설정
- 비활성화(OFF) -> 테이블 단위의 압축 성공, 압축 실행 회숫만 수집
- 테이블 단위로 수집된 정보: `information_schema.INNODB_CMP` 테이블에 기록
- 인덱스 단위로 수집된 정보: `information_schema.INNODB_CMP_PER_INDEX` 테이블에 기록
- `innodb_compression_level`: InnoDB의 테이블 압축은 zlib 압축 알고리즘 지원, 시스템 변수 이용 -> 압축률 설정(0~9)
- 값 ↓ -> 압축 속도 ↑, 저장공간 ↑ / 값 ↑ -> 속도 ↓, 압축률 ↑
- 기본값: 6(압축 속도와 압축률 모두 중간 정도로 선택한 값)
압축 속도 == 자원 소모량- 압축 속도가 빨라진다 == CPU 자원 적게 사용한다
- `innodb_compression_failure_threshold_pct`와 `innodb_compression_pad_pct_max`
- 테이블 단위로 압축 실패율 > `innodb_compression_failure_threshold_pct` 시스템 설정값
-> 압축을 실행하기 전 원본 데이터 페이지의 끝에 의도적으로 일정 크기의 빈 공간 추가- 추가된 빈 공간 -> 압축률 ↑ => 압축 결과 < `KEY_BLOCK_SIZE` 효과
추가된 빈 공간 == 패딩(Padding) - 압축 실패율 ↑ -> 계속 증가된 크기 가짐, 추가할 수 있는 패딩 공간의 최대 크기는 `innodb_compression_pad_pct_max` 설정값 이상을 넘을 수 X
`innodb_compression_pad_pct_max` 시스템 설정값 % 설정 == 전체 데이터 페이지 크기 대비 패딩 공간의 비율
- 추가된 빈 공간 -> 압축률 ↑ => 압축 결과 < `KEY_BLOCK_SIZE` 효과
- 테이블 단위로 압축 실패율 > `innodb_compression_failure_threshold_pct` 시스템 설정값
- `innodb_log_compressed_pages`: 서버가 비정상적으로 종료됐다가 다시 시작되는 경우 압축 알고리즘(zlib)의 버전 차이가 있더라도 복구 과정이 실패하지 않도록 InnoDB 스토리지 엔진은 압축된 데이터 페이지 그대로 리두 로그에 기록
- 압축 알고리즘을 업그레이드할 때 도움
But, 데이터 페이지를 통째로 리두 로그에 저장 -> 리두 로그의 증가량에 상당한 영향 미칠 수 있음- 압축 적용 후 리두 로그 용량이 매우 빠르게 증가 or 버퍼 풀로부터 더티 페이지가 한꺼번에 많이 기록되는 패턴으로 바뀌었다면 `innodb_log_compressed_pages` 시스템 변수 OFF로 설정한 후 모니터링해보는 것이 좋음
- 기본값: ON (가능하면 유지)
- 압축 알고리즘을 업그레이드할 때 도움
출처
GitHub - wikibook/realmysql80: 《Real MySQL 8.0》 예제 파일
《Real MySQL 8.0》 예제 파일. Contribute to wikibook/realmysql80 development by creating an account on GitHub.
github.com
'📓 > 데이터베이스' 카테고리의 다른 글
| [Real MySQL 8.0 1] 08 인덱스 - 1. 디스크 읽기 방식 / 2. 인덱스란? / 3. B-Tree 인덱스 (0) | 2025.01.27 |
|---|---|
| [Real MySQL 8.0 1] 07 데이터 암호화 (0) | 2025.01.27 |
| [Real MySQL 8.0 1] 05 트랜잭션과 잠금 (0) | 2025.01.24 |
| [Real MySQL 8.0 1] 04 아키텍처 - 3. MyISAM 스토리지 엔진 아키텍처 / 4. MySQL 로그 파일 (0) | 2025.01.24 |
| [Real MySQL 8.0 1] 04 아키텍처 - 1. MySQL 엔진 아키텍처 (0) | 2025.01.23 |