
7. 멀티 밸류 인덱스
모든 인덱스는 레코드 1건 -> 1개의 인덱스 키 값 가짐 (전문 검색 인덱스 제외)
= 인덱스 키 : 데이터 레코드는 1:1 관계 가짐
멀티 밸류(Multi-Value) 인덱스: 하나의 데이터 레코드가 여러 개의 키 값을 가질 수 있음
-> 일반적인 RDBMS 기준: 정규화 위배
But, JSON 데이터 타입 지원 -> JSON의 배열 타입의 필드에 저장된 원소들에 대한 인덱스 요건 발생
신용 정보 점수를 배열로 JSON 타입 칼럼에 저장하는 테이블
CREATE TABLE user (
user_id BIGINT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(10),
last_name VARCHAR(10),
credit_info JSON,
INDEX mx_creditscores ( (CAST(credit_info->'$.credit_scores' AS UNSIGNED ARRAY)) )
);
INSERT INTO user VALUES (1, 'Matt', 'Lee', '{"credit_scores":[360, 353, 351]}');
일반적인 조건 방식 사용 X, `MEMBER OF()`, `JSON_CONTAINS()`, `JSON_OVERLAPS()` 함수 이용
SELECT * FROM user WHERE 360 MEMBER OF(credit_info->'$.credit_scores');
EXPLAIN SELECT * FROM user WHERE 360 MEMBER OF(credit_info->'$.credit_scores');8. 클러스터링 인덱스
클러스터링: 여러 개를 하나로 묶는다는 의미
-> 테이블의 레코드를 비슷한 것(프라이머리 키 기준)들끼리 묶어서 저장하는 형태로 구현
=> 비슷한 값을 동시에 조회하는 경우 ↑ 때문 (InnoDB 스토리지 엔진에서만 지원)
1) 클러스터링 인덱스
- 테이블의 프라이머리 키에 대해서만 적용/ 프라이머리 키 값이 비슷한 레코드끼리 묶어서 저장
- 프라이머리 키 값 -> 레코드 저장 위치 결정
- 프라이머리 키 값 변경 -> 레코드의 물리적인 저장 위치 변경
- 프라이머리 키 값 의존도 ↑
- 테이블 레코드의 저장 방식 (인덱스 알고리즘 X)
- 클러스터링 인덱스 = 클러스터링 테이블
- 클러스터링 키 = 프라이머리 키
- InnoDB: 프라이머리 키 기반 검색 빠름/ 레코드 저장 or 프라이머리 키 변경 느림
- 테이블 구조는 비슷 But, 리프 노드 차이
- B-Tree: 세컨더리 인덱스 저장
- 클러스터링 인덱스: 레코드의 모든 칼럼이 같이 저장
=> 그 자체가 하나의 거대한 인덱스 구조로 관리
클러스터링 테이블의 데이터 레코드 변화: 프라이머리 키(employees 테이블의 `emp_no`)를 변경하는 문장 실행
UPDATE tb_test SET emp_no=100002 WHERE emp_no=100007;`emp_no`가 100007인 레코드는 3번 페이지에 저장 -> `emp_no`가 100002로 변경되면서 2번 페이지로 이동
프라이머리 키 or 인덱스 키 값 변경 -> MyISAM 테이블 or 기타 InnoDB를 제외한 테이블의 데이터 레코드 위치 변경 X
데이터 레코드가 `INSERT` 될 때 데이터 파일의 끝(or 임의의 빈 공간)에 저장
-> 한번 결정된 위치 변경 X/ 레코드가 저장된 주소(로우 아이디(ROW-ID))
: MySQL 내부적으로 레코드를 식별하는 아이디로 인식
-> 일부 DBMS) 사용자가 값을 직접 조회 or 쿼리의 조건으로 사용 But, MySQL) 사용자에게 노출 X
프라이머리 키 X InnoDB 테이블: 클러스터링 키 선택
- (기본) 프라이머리 키
- `NOT NULL` 옵션의 유니크 인덱스(UNIQUE INDEX) 중에서 첫 번째 인덱스
- 자동으로 유니크한 값을 가지도록 증가되는 칼럼을 내부적으로 추가
InnoDB 스토리지 엔진) 적절한 클러스터링 키 후보 찾지 X -> 내부적으로 레코드의 일련번호 칼럼 생성
자동으로 추가된 프라이머리 키(일련번호 칼럼): 사용자에게 노출 X, 쿼리 문장에 명시적으로 사용 X
= 프라이머리 키 or 유니크 인덱스 X InnoDB 테이블에서 의미 X 숫자 값으로 클러스터링 되는 것 -> 혜택 X
=> 클러스터링 인덱스는 테이블 당 하나만 가질 수 있는 혜택 -> 프라이머리 키 명시적으로 생성
2) 세컨더리 인덱스에 미치는 영향
클러스터링 X 테이블(ex. MyISAM or MEMORY 테이블): `INSERT`될 때 처음에 저장된 공간에서 절대 이동 X
(데이터 레코드가 저장된 주소 -> 내부적인 레코드 아이디(ROWID) 역할)
ROWID ~> 프라이머리키 or 세컨더리 인덱스) 실제 레코드 찾아옴
=> 프라이머리 키 != 세컨더리 인덱스 구조적 차이
IF. 클러스터링 O 테이블(ex. InnoDB): 세컨더리 인덱스가 실제 레코드가 저장된 주소 가지고 있다면?
-> 클러스터링 키 값 변경될 때마다 데이터 레코드 주소 변경 -> 해당 테이블의 모든 인덱스에 저장된 주솟값 변경
=> 세컨더리 인덱스: 해당 레코드 주소 X 프라이머리 키 값 저장 O -> 오버헤드 제거
employees 테이블에서 `first_name` 칼럼으로 검색
CREATE TABLE employees (
emp_no INT NOT NULL,
first_name VARCHAR(20) NOT NULL,
PRIMARY KEY (emp_no),
INDEX ix_firstname (first_name)
);
SELECT * FROM employees WHERE first_name='Aamer';- MyISAM: `ix_firstname` 인덱스 검색 -> 레코드 주소 확인 후, 레코드 주소로 최종 레코드 가져옴
- InnoDB: `ix_firstname` 인덱스 검색 -> 레코드의 프라이머리 키 값 확인 후, 프라이머리 키 인덱스 검색해서 최종 레코드 가져옴
=> InnoDB가 더 복잡하게 처리 But, InnoDB 테이블에서 프라이머리 키(클러스터링 인덱스) 더 큰 장점 제공 -> 성능 저하 걱정 X
3) 클러스터링 인덱스의 장점과 단점
장점
- 프라이머리 키(클러스터링 키)로 검색 -> 처리 성능 매우 ↑
- 특히, 프라이머리 키를 범위 검색하는 경우 매우 빠름
- 테이블의 모든 세컨더리 인덱스가 프라이머리 키 가지고 있음 -> 인덱스만으로 처리될 수 있는 경우 ↑ (=> 커버링 인덱스)
=> 빠른 읽기(`SELECT`)
단점
- 테이블의 모든 세컨더리 인덱스가 클러스터링 키 갖음 -> 클러스터링 키 값 ↑ -> 전체적으로 인덱스 크기 ↑
- 세컨더리 인덱스 ~> 검색 -> 프라이머리 키로 다시 한 번 검색해야 함 => 처리 성능 ↓
- `INSERT`: 프라이머리 키에 의해 레코드 저장 위치 결정 -> 처리 성능 ↓
- 프라이머리 키 변경: 레코드 `DELETE`, `INSERT`하는 작업 필요 -> 처리 성능 ↓
=> 느린 쓰기(`INSERT`, `UPDATE`, `DELETE`)
4) 클러스터링 테이블 사용 시 주의사항
클러스터링 인덱스 키의 크기
클러스터링 테이블은 모든 세컨더리 인덱스가 프라이머리 키(클러스터링 키) 값 포함
-> 프라이머리 키 크기 ↑ -> 세컨더리 인덱스 크기 ↑ (테이블에 세컨더리 인덱스 4~5개 생성 => 세컨더리 인덱스 급격히 ↑)
| 프라이머리 키 크기 | 레코드당 증가하는 인덱스 크기 | 100만 건 레코드 저장 시 증가하는 인덱스 크기 |
| 10바이트 | 10바이트 * 5 = 50바이트 | 50바이트 * 1,000,000 = 47MB |
| 50바이트 | 50바이트 * 5 = 250바이트 | 250바이트 * 1,000,000 = 238MB |
인덱스 ↑ -> 메모리 ↑ => InnoDB 테이블의 프라이머리 키 신중하게 선택
프라이머리 키는 AUTO-INCREMENT보다는 업무적인 칼럼으로 생성(가능한 경우)
InnoDB의 프라이머리 키는 클러스터링 키로 사용, 이 값에 의해 레코드 위치 결정
프라이머리 키로 검색(특히, 범위로 ↑ 레코드 검색) -> 클러스터링 X 테이블에 비해 매우 빠르게 처리
클러스터링 X 테이블(ex. MyISAM): 성능의 차이 별로 X But, InnoDB: 차이 ↑
=> 칼럼의 크기가 크더라도 업무적으로 해당 레코드 대표 O -> 그 칼럼을 프라이머리 키로 설정
프라이머리 키는 반드시 명시할 것
InnoDB 테이블에서 프라이머리 키 정의 X -> 내부적으로 일련번호 칼럼 추가
=> 자동으로 추가된 칼럼은 사용자에게 보이지 X -> 사용자 접근(사용) X
= `AUTO_INCREMENT` 칼럼 생성하고 프라이머리 키 설정(사용자 사용 O -> 더 좋음)
ROW 기반의 복제 or InnoDB Cluster) 모든 테이블이 프라이머리 키를 가져야만 정상적인 복제 성능 보장
AUTO-INCREMENT 칼럼을 인조 식별자로 사용한 경우
여러 개의 칼럼이 복합으로 프라이머리 키 만들어지는 경우 -> 프라이머리 키의 크기 길어질 때 있음
- 세컨더리 인덱스 필요 X -> 길어도 그대로 프라이머리 키 사용
- 세컨더리 인덱스 필요 O -> `AUTO_INCREMENT` 칼럼 추가, 프라이머리 키로 설정
- 인조 식별자(Surrogate key): 프라이머리 키를 대체하기 위해 인위적으로 추가된 프라이머리 키
- `INSERT` 위주의 테이블 성능 향상에 도움
9. 유니크 인덱스
- 인덱스보다 제약 조건에 가까움
- 테이블 or 인덱스에 같은 값이 2개 이상 저장 X
- NULL은 특정 값 X -> 2개 이상 저장 O
1) 유니크 인덱스와 일반 세컨더리 인덱스의 비교
유니크 인덱스 != 유니크 X 일반 세컨더리 인덱스 구조상 차이
인덱스 읽기
- 유니크 인덱스: 1건만 읽음
- 유니크 X 세컨더리 인덱스: 레코드 1건 더 읽어야 함 => 느리다? (X)
- 디스크 읽기 X CPU에서 칼럼값을 비교하는 작업 -> 성능상 영향 거의 X
=> 유니크 X 세컨더리 인덱스: 중복된 값 O -> 읽어야 할 레코드 ↑ => 속도 느림 (인덱스 자체 특성 때문 X)
=> 읽어야 할 레코드 건수 같다면 성능상 차이 X
인덱스 쓰기
새로운 레코드 `INSERT` or 인덱스 칼럼의 값 변경
- 유니크 인덱스: 키 값을 쓸 때는 중복값 여부 체크 -> 느림
- 중복된 값 체크: 읽기 잠금 / 쓰기: 쓰기 잠금 -> 데드락 빈번히 발생
- 인덱스 저장 or 변경 작업 빨리 처리 But, (필수) 중복 체크 -> 작업 자체 버퍼링 X => 느림
- InnoDB 스토리지 엔진) 인덱스 키의 저장을 버퍼링 -> 체인지 버퍼(Change Buffer) 사용
2) 유니크 인덱스 사용 시 주의사항
하나의 테이블에서 같은 칼럼에 유니크 인덱스, 일반 인덱스/프라이머리 키 중복 생성
-> 유니크 인덱스: 일반 인덱스와 같은 역할 => 불필요한 중복
- 유일성이 꼭 보장돼야 하는 칼럼 -> 유니크 인덱스 생성
- 꼭 필요 X -> 불필요하게 생성 X 세컨더리 인덱스 생성
유니크 인덱스(`ux_nickname`) O -> `ix_nickname` 인덱스 필요 X
CREATE TABLE tb_unique (
id INTEGER NOT NULL,
nick_name VARCHAR(100),
PRIMARY KEY (id),
UNIQUE INDEX ux_nickname (nick_name),
INDEX ix_nickname (nick_name)
);
10. 외래키
InnoDB 스토리지 엔진에서만 생성할 수 있음
외래키 제약 설정- > 자동으로 연관되는 테이블의 칼럼에 인덱스까지 생성
외래키가 제거 X 상태에서 자동으로 생성된 인덱스 삭제 X
2가지 특징
- 테이블의 변경(쓰기 잠금)이 발생하는 경우에만 잠금 경합(잠금 대기) 발생
- 외래키와 연관 X 칼럼의 변경은 최대한 잠금 경합(잠금 대기) 발생 X
CREATE TABLE tb_parent (
id INT NOT NULL,
fd VARCHAR(100) NOT NULL, PRIMARY KEY (id)
) ENGIN=InnoDB;
CREATE TABLE tb_child (
id INT NOT NULL,
pid INT DEFAULT NULL, -- // parent.id 칼럼 참조
fd VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (id),
KEY ix_parentid (pid),
CONSTRAINT child_ibfk_1 FOREIGN KEY (pid) REFERENCES tb_parent (id) ON DELETE CASCADE
) ENGIN=InnoDB;
INSERT INTO tb_parent VALUES (1, 'parent-1'), (2, 'parent-2');
INSERT INTO tb_child VALUES (100, 1, 'child-100');
1) 자식 테이블의 변경이 대기하는 경우
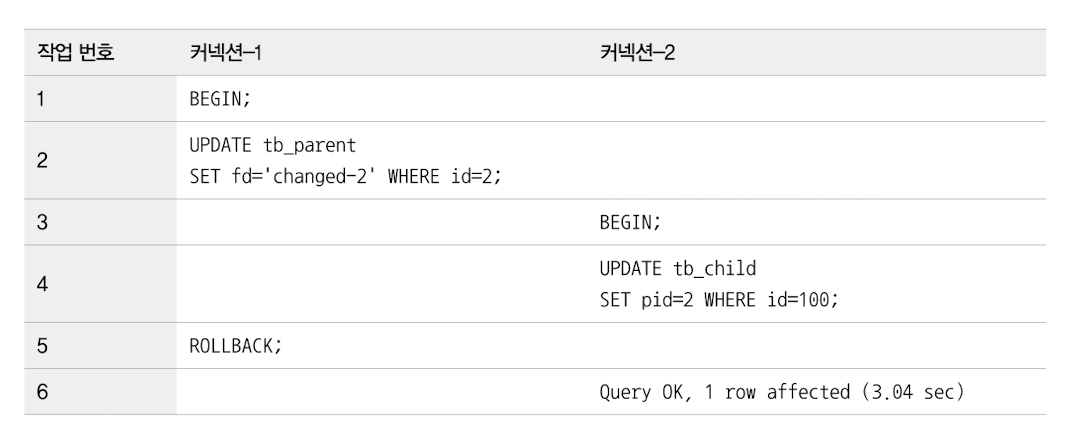
- 커넥션-1: 트랜잭션 시작
/ 부모(tb_parent) 테이블에서 `id`가 2인 레코드에 `UPDATE` 실행 -> 쓰기 잠금 획득 - 커넥션-2: 자식 테이블(tb_child)의 외래키 칼럼(부모의 키 참조하는 칼럼)인 pid를 2로 변경하는 쿼리 실행
-> 쿼리(4번): 부모 테이블의 변경 작업 완료될 때까지 대기 - 커넥션-1: `ROLLBACK` or `COMMIT`으로 트랜잭션 종료
- 커넥션-2: 대기 중이던 작업 즉시 처리
= 자식 테이블의 외래 키 칼럼의 변경(`INSERT`, `UPDATE`)은 부모 테이블의 확인 필요
-> 부모 테이블의 해당 레코드가 쓰기 잠금 걸려 있으면 해제될 때까지 대기
=> 자식 테이블의 외래키(`pid`)가 아닌 컬럼(tb_child 테이블의 `fd`)의 변경: 외래키로 인한 잠금 확장(위의 예제) 발생 X
2) 부모 테이블의 변경 작업이 대기하는 경우

- 커넥션-1: 부모 키 '1'을 참조하는 자식 테이블의 레코드 변경 -> tb_child 테이블의 레코드에 대한 쓰기 잠금 획득
- 커넥션-2: tb_parent 테이블에서 id가 1인 레코드 삭제
-> 쿼리(4번): tb_child 테이블의 레코드에 대한 쓰기 잠금 해제될 때까지 대기- 자식 테이블(tb_child)이 생성될 때 정의된 외래키의 특성(`ON DELETE CASCADE`)
-> (부모 레코드 삭제 -> 자식 레코드도 동시에 삭제)
- 자식 테이블(tb_child)이 생성될 때 정의된 외래키의 특성(`ON DELETE CASCADE`)
출처
GitHub - wikibook/realmysql80: 《Real MySQL 8.0》 예제 파일
《Real MySQL 8.0》 예제 파일. Contribute to wikibook/realmysql80 development by creating an account on GitHub.
github.com
'📓 > 데이터베이스' 카테고리의 다른 글
| [Real MySQL 8.0 1] 08 인덱스 - 4. R-Tree 인덱스 / 5. 전문 검색 인덱스 / 6. 함수 기반 인덱스 (0) | 2025.07.30 |
|---|---|
| Redis - 동시성 / 아키텍처 (2) | 2025.02.24 |
| Memcached(멤캐시드) vs. Redis(레디스) (0) | 2025.02.24 |
| Pessimistic Lock(비관적 락) vs. Optimistic Lock(낙관적 락) (0) | 2025.02.23 |
| Trigger(트리거) & Procedure(프로시저) (0) | 2025.02.23 |