
4. R-Tree 인덱스
공간 인덱스(Spatial Index)
- R-Tree 알고리즘 이용해 2차원 데이터 인덱싱, 검색하는 목적의 인덱스
- 내부 메커니즘 B-Tree와 유사
- B-Tree 인덱스 구성하는 칼럼의 값 1차원 스칼라 값
- R-Tree 인덱스: 2차원 공간 개념의 값
MySQL 공간 확장에 포함된 3가지 기능
- 공간 데이터 저장할 수 있는 데이터 타입
- 공간 데이터 검색 위한 공간 인덱스(R-Tree 알고리즘)
- 공간 데이터의 연산 함수(거리 or 포함 관계의 처리)
1) 구조 및 특성
공간 정보의 저장 및 검색 -> 기하학적 도형(Geometry) 정보 관리할 수 있는 데이터 타입 제공
POINT, LINE, POLYGON, GEOMETRY(3개 슈퍼 타입 -> 나머지 객체 모두 저장 O)
MBR(Minimum Bounding Rectangle): 해당 도형을 감싸는 최소 사각형의 크기
-> 사각형들의 포함 관계를 B-Tree 형태로 구현한 인덱스 => R-Tree 인덱스
X좌표, Y좌표만 있는 포인트 데이터 -> 하나의 도형 객체 될 수 있음
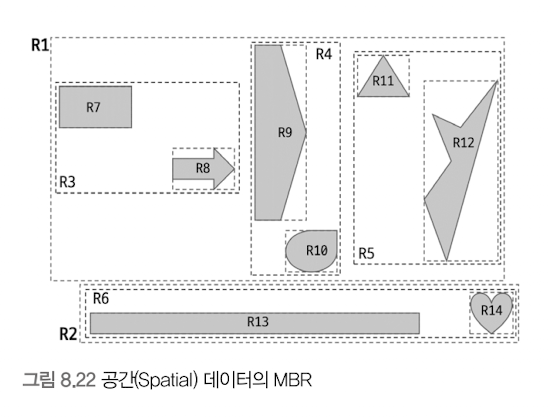
도형들의 MBR을 3개의 레벨로 나눠서 그림
- 최상위 레벨:R1, R2
- R-Tree의 루트 노드에 저장
- 차상위 레벨: R3, R4, R5, R6
- 중간 크기의 MBR (도형 객체의 그룹)
- R-Tree의 브랜치 노드에 저장
- 최하위 레벨: R7 ~ R14
- 각 도형 데이터의 MBR
- R-Tree의 리프 노드에 저장


2) R-Tree 인덱스의 용도
R-Tree (공간 인덱스)
- MBR 정보 이용해 B-Tree 형태로 인덱스 구축 -> Rectangle + B-Tree
- 각 도형의 포함 관계
-> 포함 관계 비교하는 함수(`ST_Contains()` or `ST_Within()`)로 검색을 수행하는 경우에만 인덱스 이용 O - ex. 현재 사용자의 위치로부터 반경 5km 이내의 음식점 검색
- `ST_Distance()`, `ST_Distance_Sphere()`: 공간 인덱스 효율적 사용 X
-> `ST_Contains()` or `ST_Within()` 이용해 거리 기반의 탐색
- 각 도형의 포함 관계
- WGS84(GPS) 기준으 위도, 경도 좌표 저장에 주로 사용
- CAD/CAM 소프트웨어 or 회로 디자인 등 좌표 시스템에 기반을 둔 정보에 대해 모두 적용 O
기준점: P / 기준점으로부터 반경 거리 5km 이내의 점(위치) 검색
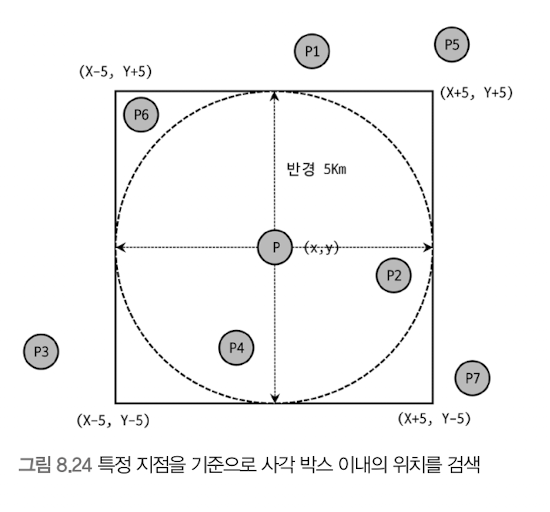
- 사각 점선 상자에 포함되는(`ST_Contains()` or `ST_Within()`) 점 검색
- `ST_Contains()` or `ST_Within()` 연사: 사각형 박스와 같은 다각형(Polygon)으로만 연산 O
-> 반경 5km를 그리는 원을 포함하는 최소 사각형(MBR)으로 포함 관계 비교 수행
- `ST_Contains()` or `ST_Within()` 연사: 사각형 박스와 같은 다각형(Polygon)으로만 연산 O
- 점 P6: 기준점 P로부터 반경 5km 이상 But, 최소 사각형 내 포함
- -> P6 빼고 결과 조회 시 조금 더 복잡한 비교 필요
- 1. P6 포함해서 비교
-- // ST_Contains() or ST_Within() 이용 -> 사각 상자에 포함된 좌표 Px만 검색
SELECT * FROM tb_location
WHERE ST_Contains(사각 상자, px);
SELECT * FROM tb_location
WHERE ST_Within(px, 사각 상자);- 2. P6 반드시 제거 -> `ST_Contains()` 비교 결과에 대해 `ST_Distance_Sphere()` 이용해 다시 한 번 필터링
SELECT * FROM tb_location
WHERE ST_Contains(사각상자, px) -- // 공간 좌표 Px가 사각 상자에 포함되는지 비교
AND ST_Distance_Sphere(p, px) <= 5*1000 /* 5km */;5. 전문 검색 인덱스
전문(Full Text) 검색: 문서 내용 전체 인덱스화 -> 특정 키워드가 포함된 문서 검색
-> InnoDB(MySQL 8.0 버전부터 기본 스토리지 엔진) or MyISAM 스토리지 엔진에서 제공하는 일반적인 용도의 B-Tree 인덱스 사용 X
=> 전문 검색(Full Text search) 인덱스: 문서 전체 에 대한 분석과 검색을 위한 인덱싱 알고리즘
1) 인덱스 알고리즘
문서 본문의 내용에서 사용자가 검색하게 될 키워드 분석 후 인덱스 구축 -> 빠른 검색용으로 사용
문서의 키워드를 인덱싱하는 방법
- 단어의 어근 분석
- n-gram 분석 알고리즘
어근 분석 알고리즘
2가지 과정을 거쳐서 색인 작업 수행
- 불용어(Stop Word) 처리: 가치 X 단어 모두 필터링해서 제거하는 작업
- 개수 ↓ -> 코드에 모두 상수로 정의해서 사용
- 유연성 -> 불용어 자체를 데이터베이스화 -> 사용자) 추가/삭제
- 어근 분석(Stemming)
n-gram 알고리즘
- n-gram: 본문 -> 무조건 몇 글자씩 잘라서 인덱싱하는 방법
- n: 인덱싱할 키워드의 최소 글자 수 ( 2(Bi)-gram)
- 형태소 분석보다 알고리즘 단순, 국가별 언어에 대한 이해와 준비 X But, 만들어진 인덱스 크기 ↑
To be or not to be. That is the question


- 띄어쓰기(공백)와 마침표(.) 기준으로 10개의 단어로 구분, 2글자씩 중첩해서 토큰으로 분리
- ex. 10글자 단어 -> 2-gram 알고리즘: (10-1)개의 토큰으로 구분
- 구분된 토큰 -> 인덱스에 저장 / 중복된 토큰 -> 하나의 인덱스 엔트리로 병합되어 저장
- 생성된 토큰들에 대해 불용어 걸러냄
- 불용어와 동일 or 불용어 포함 -> 걸러서 버림
MySQL 서버에 내장된 불용어 확인
SELECT * FROM information_schema.INNODB_FT_DEFAULT_STOPWORD;
불용어 변경 및 삭제
전문 검색 인덱스의 불용어 처리 무시
- 스토리지 엔진 관계 X MySQL 서버의 모든 전문 검색 인덱스에 대해 불용어 완전히 제거
- `ft_stopword_file=''`
- 서버의 내장 불용어 비활성화/ 설정 파일(`my.cnf`)
- 시작될 때만 인지 -> 설정 변경 시 서버 재시작해야 변경사항 반영
- 사용자 정의 불용어 적용할 때도 사용 O
- 사용자가 직접 정의한 불용어 목록을 저장한 파일 경로 설정 -> 해당 경로 파일에서 불용어 목록 가져와 적용
- `ft_stopword_file=''`
- InnoDB 스토리지 엔진을 사용하는 테이블의 전문 검색 인덱스에 대해서만 불용어 처리 무시
- `innodb_ft_enable_stopword=OFF`
- 동적인 시스템 변수 -> 서버 실행 중인 상태에서도 변경 O
- MySQL 서버의 다른 스토리지 엔진(MyISAM 스토리지 엔진) 사용하는 테이블 -> 내장 불용어 처리 사용
- `innodb_ft_enable_stopword=OFF`
사용자 정의 불용어 사용
- 불용어 목록 파일로 저장 -> 파일 경로를 `ft_stopword_file` 설정에 등록
- `ft_stopword_file='/data/my_custom_stopword.txt'`
- 불용어의 목록 -> 테이블로 저장(InnoDB 스토리지 엔진을 사용하는 테이블의 검색 엔진에서만 사용)
- 불용어 목록을 변경한 후 전문 검색 인덱스가 생성돼야만 변경된 불용어가 적용됨
CREATE TABLE my_stopword(value VARCHAR(30)) ENGIHE = INNODB;
INSERT INTO my_stopword(value) VALUES ('MySQL');
SET GLOBAL innodb_fit_server_stopword_table='mydb/my_stopword';
ALTER TABLE tb_bi_gram
ADD FULLTEXT INDEX fx_title_body(title, body) WITH PARSER ngram;2) 전문 검색 인덱스의 가용성
전문 검색 인덱스 사용하기 위한 2가지 조건
- 쿼리가 `MATCH ... AGAINST ...` 문법 사용
- 테이블이 전문 검색 대상 컬럼에 대해서 전문 인덱스 보유
- 전문 검색 인덱스 구성하는 칼럼들은 `MATCH` 절의 괄호 안에 모두 명시돼야 함
`doc_body` 칼럼에 전문 검색 인덱스 생성
CREATE TABLE tb_test (
doc_id INT,
doc_body TEXT,
PRIMARY KEY (doc_id),
FULLTEXT KEY fx_docbody (doc_body) WITH PARSER ngram
) ENGINE=InnoDB;
풀 테이블 스캔으로 쿼리 처리
SELECT * FROM tb_test WHERE doc_body LIKE '%애플%;
전문 검색 인덱스 사용
SELECT * FROM tb_test
WHERE MATCH(doc_body) AGAINST('애플' IN BOOLEAN MODE);6. 함수 기반 인덱스
일반적인 인덱스: 칼럼의 값 일부(칼럼의 값 앞부분) or 전체에 대해서만 인덱스 생성 허용
But, 컬럼의 값 변형해서 만들어진 값에 대해 인덱스 구축 필요 -> 함수 기반 인덱스 활용
함수 기반 인덱스 구현 방법
- 가상 컬럼 이용한 인덱스
- 함수 이용한 인덱스
-> 인덱싱할 값 계산하는 과정 차이 O / 내부적인 구조 및 유지관리 방법 B-Tree 인덱스와 동일
1) 가상 칼럼을 이용한 인덱스
사용자 정보 저장하는 테이블
CREATE TABLE user (
user_id BIGINT,
first_name VARCHAR(10),
last_name VARCHAR(10),
PRIMARY KEY (user_id)
);
`first_name`, `last_name` 합쳐서 검색
-> `full_name` 칼럼 추가, 모든 레코드에 대해 `full_name` 업데이트
=> `full_name` 컬럼에 대해 인덱스 생성 O
MySQL 8.0 버전부터: 가상 컬럼 추가, 가상 컬럼에 인덱스 생성 O
ALTER TABLE user
ADD full_name VARCHAR(30) AS (CONCAT(first_name,' ',last_name)) VIRTUAL,
ADD INDEX ix_fullname (full_name);
`full_name` 인덱스 이용 ->`full_name` 칼럼에 대한 검색
EXPLAIN SELECT * FROM user WHERE full_name='Matt Lee';
가상 컬럼이 `VIRTUAL` or `STORED` 어떤 옵션이든 관계 X 해당 가상 컬럼에 인덱스 생성 O
테이블에 새로운 컬럼을 추가하는 것과 같은 효과 -> (-) 실제 테이블 구조 변경
2) 함수를 이용한 인덱스
MySQL 8.0 버전부터: 테이블 구조 변경 X 함수 직접 사용하는 인덱스 생성 O
CREATE TABLE user (
user_id BIGINT,
first_name VARCHAR(10),
last_name VARCHAR(10),
PRIMARY KEY (user_id)
INDEX ix_fullname ((CONCAT(first_name,' ',last_name)))
);(필수) 조건절에 함수 기반 인덱스에 명시된 표현식이 그대로 사용돼야 함
IF. 함수 생성 시 명시된 표현식 != 쿼리의 `WHERE` 조건절에 사용된 표현식
-> MySQL 옵티마이저) 다른 표현식으로 간주 => 함수 인덱스 사용 X
EXPLAIN SELECT * FROM user WHERE CONCAT(first_name,' ',last_name)='Matt Lee';IF. 옵티마이저) 표시하는 실행 계획 `ix_fullname` 인덱스 사용 X
-> `CONCAT` 함수에 사용된 공백 문자 리터럴 때문일 가능성 ↑
=> 3개 시스템 변수의 값을 동일 콜레이션으로 일치시킨 후 다시 테스트 수행
(`collation_connection`, `collation_database`, `collation_server`)
출처
GitHub - wikibook/realmysql80: 《Real MySQL 8.0》 예제 파일
《Real MySQL 8.0》 예제 파일. Contribute to wikibook/realmysql80 development by creating an account on GitHub.
github.com
'📓 > 데이터베이스' 카테고리의 다른 글
| [Real MySQL 8.0 1] 08 인덱스 - 7. 멀티 밸류 인덱스 / 8. 클러스터링 인덱스 (0) | 2025.07.30 |
|---|---|
| Redis - 동시성 / 아키텍처 (2) | 2025.02.24 |
| Memcached(멤캐시드) vs. Redis(레디스) (0) | 2025.02.24 |
| Pessimistic Lock(비관적 락) vs. Optimistic Lock(낙관적 락) (0) | 2025.02.23 |
| Trigger(트리거) & Procedure(프로시저) (0) | 2025.02.23 |