
1장 컴퓨터는 데이터에서 배운다

1. 데이터를 지식으로 바꾸는 지능적인 시스템 구축
머신 러닝
- 20세기 후반, 자기 학습(self-learning) 알고리즘(: 데이터 -> 지식 추출 -> 예측)과 관련된 인공지능(Artificial Intelligence, AI)의 하위 분야
- 데이터에서 더 효율적으로 지식 추출 -> 예측 모델과 데이터 기반의 의사 결정 성능 점진적 ↑
- ex. 견고한 이메일 스팸 필터, 편리한 텍스트와 음성 인식 소프트웨어, 믿을 수 있는 웹 검색 엔진, 체스 대결 프로그램, 자율 주행 자동차, 의료 어플리케이션,...
2. 머신 러닝의 세 가지 종류
| 지도 학습 | 레이블된 데이터 직접 피드백 출력 및 미래 예측 |
| 비지도 학습 | 레이블 및 타깃 X 피드백 X 데이터에서 숨겨진 구조 찾기 |
| 강화 학습 | 결정 과정 보상 시스템 연속된 행동에서 학습 |
1) 지도 학습(supervised learning)
목적: 레이블(label)된 훈련 데이터 -> 모델 학습 -> 본 적 X 미래 데이터에 대해 예측
지도: 희망하는 출력 신호(레이블)가 있는 일련의 샘플(데이터 입력)
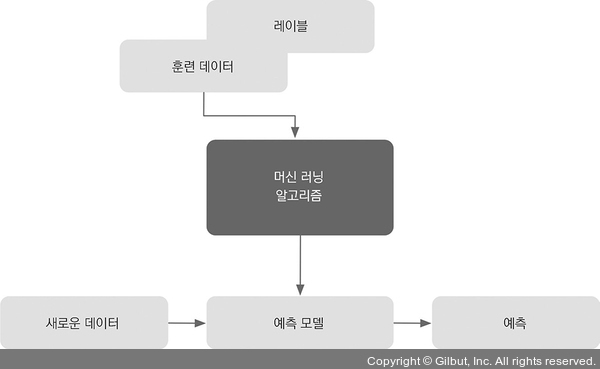
ex. 스팸 메일 필터링
레이블된 이메일 데이터셋에서 지도 학습 머신 러닝 알고리즘 -> 모델 훈련
이메일 데이터셋: 스팸/스팸X 이메일
훈련된 모델: 새로운 이메일 -> 두 개의 범주(category) 중 어디 속하는지 예측
① 분류(classification): 클래스 레이블 예측
목적: 과거 관측 기반 -> 새로운 샘플의 범주형 클래스 레이블 예측
클래스 레이블: 이산적(discrete), 순서X -> 샘플이 속한 그룹
ex. 스팸 메일 감지 -> 이진 분류(binaray classification)
- 음성 클래스(negative class)로 레이블(뺄셈 기호)
- 양성 클래스(positive class)로 레이블(덧셈 기호)
각 샘플이 두 값에 연관 => 2차원 데이터셋
지도 학습 알고리즘 -> 두 클래스 구분할 수 있는 규칙 학습 -> 규칙: 점선으로 나타난 결정 경계(decision boundary)
새로운 데이터 -> 두 개 범주 중 하나로 분류
두 개 이상 클래스 레이블 가진 경우
지도 학습 알고리즘으로 학습한 예측 모델: 훈련 데이터셋에 있는 클래스 레이블 -> 새로운 샘플에 할당
=> 다중 분류(multiclass classification)
ex. 손으로 쓴 글자 인식
=> 분류 작업: 범주형 순서X 레이블 -> 샘플에 할당하는 것
/ 모델 훈련 시 사전에 옳은 답O
② 회귀(regression): 연속적인 출력 값 예측
- 예측 변수(predictor variable) or 설명 변수(explanatory variable) => 특성(feature)
- 연속적인 반응 변수(response variable) or 결과(outcome) => 타깃(target)
출력 값 예측 -> 두 변수 사이의 관계 찾음
ex. 수학 SAT 점수 예측
시험 공부에 투자한 시간, 최종 점수 -> 관계O -> 두 값으로 훈련 데이터 -> 모델 학습
모델: 시험에 응시하려는 학생이 공부한 시간 이용 -> 시험 점수 예측
선형 회귀(linear regression)
특성 x와 타깃 y -> 데이터 포인트와 직선 사이 거리가 최소되는 직선(평균 제곱 거리)
데이터에서 학습한 직선의 기울기, 절편 -> 새로운 데이터 출력 값 예측
2) 비지도 학습(unsupervised learning)
레이블X or 구조 알 수X 데이터
알려진 출력 값 or 보상 함수의 도움X -> 의미O 정보 추출 -> 데이터 구조 탐색
① 군집(clustering): 서브그룹 찾기
: 사전 정보X 쌓여 있는 그룹의 정보 -> 의미O 서브그룹(subgroup) or 클러스터(cluster)로 조직하는 탐색적 데이터 분석 기법
분석 과정에서 만든 각 클러스터: 어느정도 유사성 공유, 다른 클러스터와 비슷하지X 샘플 그룹 형성
클러스터링: 정보를 조직화하고 데이터에서 의미 있는 관계 유도하는 도구
ex. 마케터: 관심사 기반 -> 고객 -> 그룹 -> 각각에 맞는 마케팅 프로그램 개발
② 차원 축소(dimensionality reduction): 데이터 압축
: 관련 있는 정보 대부분 유지, 더 ↓ 차원 가진 부분 공간(subspace) -> 데이터 압축
고차원 데이터 다뤄야 하는 경우
잡음(noise) 데이터 제거 -> 특성 전처리 단계에서 적용
잡음 데이터: 특정 알고리즘의 예측 성능 ↓
데이터 시각화에 유용
ex. 고차원 특성 -> 1차원 or 2차원 or 3차원 특성 공간으로 투영 -> 3D, 2D 산점도(scsatterplot) or 히스토그램(histogram)으로 시각화
3) 강화 학습(reinforcement learning)
목적: 환경과 상호 작용 -> 시스템(에이전트(agent)) 성능 ↑
환경의 현재 상태 정보 - 보상(reward) 신호 포함 -> 지도 학습과 관련된 분야
피드백 != 정답(ground truth) 레이블 or 값
-> 보상 함수로 얼마나 행동이 좋은지를 측정한 값
에이전트는 환경과 상호 작용 -> 보상 최대화O 일련의 행동 -> 강화 학습으로 학습
탐험적인 시행착오(trial and error) 방식 or 신중하게 세운 계획
ex. 체스 게임
에이전트: 체스판의 상태(환경) -> 기물의 이동 결정
보상: 게임 종료 -> 승리 or 패배
강화 학습 에이전트 -> 환경과 상호작용 -> 보상 최대화
양의 보상/음의 보상
보상: 전체 목표를 달성하는 것
=> 행동을 수행하고 즉시 얻기 or 지연된 피드백 ~> 얻은 전체 보상 최대화
/ 에이전트의 특정 행동 보상하는 방법 정의
3. 기본 용어와 표기법 소개
- 샘플: 데이터셋에서 하나의 행(row)
- 특성(feature): 측정값은 열(column)
- 훈련 샘플 = 관측(observation), 레코드(record), 인스턴스(instance), 예시(example)
- : 데이터셋을 나타내는 테이블의 행
- 샘플: 훈련 예시의 집합
- 훈련
- : 모델 피팅(fitting)
- 모수 모델(parameteric model) - 파라미터 추정(parameter estimation)과 비슷
- 특성(x) = 예측 변수(predictor variable), 변수, 입력, 속성(attribute), 공변량(covariate)
- : 데이터 테이블이나 데이터 행렬의 열
- 타깃(y) = 결과(outcome), 출력(output), 반응 변수, 종속 변수(dependent variable), (클래스)레이블(label), 정답(ground truth)
- 손실함수(loss function) = 비용 함수(cost function)
- 손실 함수: 하나의 데이터 포인트에 대해 측정한 손실
- 비용 함수: 전체 데이터셋에 대해 계산한 손실(평균 or 합)
4. 머신 러닝 시스템 구축 로드맵(roadmap)

전처리
: 데이터 형태 갖추기
최적의 성능 -> 선택된 특성이 같은 스케일을 지녀야 함
=> 특성 -> [0, 1] 범위 변환 or 표준 정규 분포(standard normal distribution, 평균 = 0, 단위 분산)
특성 상관 관계 ↑ -> 중복된 정보
=> 차원 축소 기법 -> 특성을 저차원 부분 공간으로 압축 -> 저장 공간 ↓, 학습 알고리즘 실행 속도 ↑, 모델의 예측 성능 ↑
데이터셋의 관련X 특성(or 잡음) ↑ = 신호 대 잡음비(Signal-to-Noise Ratio, SNR) ↓ 경우
데이터셋
- 훈련 데이터셋: 머신 러닝 모델 훈련, 최적화
- 테스트 데이터셋: 별도로 보관, 최종 모델 평가하는 맨 마지막 사용
정확도(accuracy)
: 정확히 분류된 샘플 비율
교차 검증: 모델 일반화 성능 예측 -> 훈련데이터: 훈련 데이터셋/검증 데이터셋
요약
지도학습
- 분류 모델: 샘플 -> 알려진 클래스로 분류
- 회귀 분석: 타깃 변수의 연속된 출력 예측
비지도 학습
: 레이블되지 X 데이터 -> 구조 찾는 유용한 기법, 전처리 단계 - 데이터 압축
출처
https://github.com/rickiepark/python-machine-learning-book-3rd-edition
'🤖' 카테고리의 다른 글
| [혼자 공부하는 머신러닝+딥러닝] Chapter 04 다양한 분류 알고리즘 (0) | 2024.07.25 |
|---|---|
| [혼자 공부하는 머신러닝+딥러닝] Chapter 03 회귀 알고리즘과 모델 규제 (0) | 2024.07.25 |
| [밑바닥부터 시작하는 딥러닝] CHAPTER 2 퍼셉트론 (0) | 2023.03.30 |
| [밑바닥부터 시작하는 딥러닝] CHAPTER 1 헬로 파이썬 (0) | 2023.03.28 |
| [머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로] 2장 간단한 분류 알고리즘 훈련 (0) | 2023.03.16 |