
[혼자 공부하는 컴퓨터구조+운영체제] Chapter 01 컴퓨터 구조 시작하기
Chapter 01 컴퓨터 구조 시작하기 1. 컴퓨터 구조를 알아야 하는 이유 문제 해결 프로그래밍 언어의 문법만 알고 있는 사람 -> 컴퓨터 = 코드 입력하면 결과 내놓는 '미지의 대상' 문제 상황 빠르게
debug.tistory.com
Chapter 02 데이터
1. 0과 1로 숫자를 표현하는 방법
Key Word: 비트 / 바이트 / 이진법 / 2의 보수 / 십육진법
컴퓨터는 0과 1로 모든 정보 표현, 0과 1로 표현된 정보만 이해
정보 단위
비트(bit)
- 0과 1을 나타내는 가장 작은 정보 단위
- 전구 -> 꺼짐 / 켜짐
2비트 -> (꺼짐, 꺼짐), (꺼짐, 켜짐), (켜짐, 꺼짐), (켜짐, 켜짐) => 4가지 정보 표현
=> n개의 전구로 표현할 수 있는 상태: $2^n$ 가지
= n비트는 $2^n$ 가지 정보 표현 가능
바이트(byte)
- 8개의 비트를 묶은 단위 / 8비트(8bit)
- 1바이트 = 8비트 => $2^8$(256)개의 정보 표현
1킬로바이트(kB: kilobyte): 1,000바이트(1,000byte)
1메가바이트(MB; megabyte): 1,000킬로바이트(1,000kB)
1기가바이트(GB; gigabyte): 1,000메가바이트(1,000MB)
1테라바이트(TB; terabyte): 1,000기가바이트(1,000GB)
워드(word): CPU가 한 번에 처리할 수 있는 데이터 크기
IF. CPU가 한 번에 16비트 처리 가능 -> 1워드 = 16비트 / 한 번에 32비트 처리 가능 -> 1워드 = 32 비트
- 하프 워드(half word): 워드의 절반 크기
- 풀 워드(full word): 1배 크기
- 더블 워드(double word): 2배 크기
대부분 컴퓨터의 워드 크기: 32비트 or 64비트
이진법
이진법(binary)
- 0과 1만으로 모든 숫자를 표현하는 방법
- 숫자가 1을 넘어가는 시점에 자리 올림
- 이진수: 이진법으로 표현한 수
8 표기: (수학적 표기) $1000_{(2)}$ / (코드 상 표기) 0b1000
십진법(decimal)
- 숫자가 9를 넘어가는 시점에 자리 올림
- (0 ~ 9) 10개의 숫자만으로 모든 수 표현
- 십진수: 십진법으로 표현한 수
2의 보수(two's complement)
- 어떤 수를 그보다 큰 $2^n$ 에서 뺀 값
- 음수 표현
$11_{(2)}$ 의 2의 보수: $11_{(2)}$ 보다 큰 $2^n$, 즉 $100^n - 11_{(2)} = 01_{(2)} $
= 모든 0과 1을 뒤집고(= 1의 보수), 거기에 1을 더한 값(2의 보수)
$11_{(2)}$의 모든 0과 1 뒤집으면 $00_{(2)}$, 1을 더한 값 = $01_{(2)} $
$1011_{(2)}$의 모든 0과 1을 뒤집으면 $0100_{(2)}$, 1을 더한 값 = $0101_{(2)}$
어떤 수의 2의 보수를 2번 구함 = 자기 자신
플래그(flag)
- 컴퓨터 내부에서 어떤 수 다룰 때 양수인지 음수인지 구분하기 위해 사용
- 부가 정보
=> 컴퓨터 내부에서 어떤 값을 다룰 때 부가 정보 필요한 경우 플래그 사용
십육진법
이진법은 0과 1만으로 모든 숫자 표현 -> 숫자 길이 너무 길어짐
=> 십육진법도 자주 사용
십육진법(hexadecimal)
- 15를 넘어가는 시점에 자리 올림을 하는 숫자 표현 방식
- 십진수 10, 11, 12, 13, 14, 15 -> A, B, C, D, E, F로 표현
- 한 글자로 16종류 (0 ~ 9, A ~ F)의 정보를 표현할 수 있음
- 이진수 -> 십육진수, 십육진수 -> 이진수 변환 쉬움
십육진수 15표기 : (수학적 표기) $15_{(16)}$ / (코드 상 표기) 0x15
*16진수 <-> 2진수
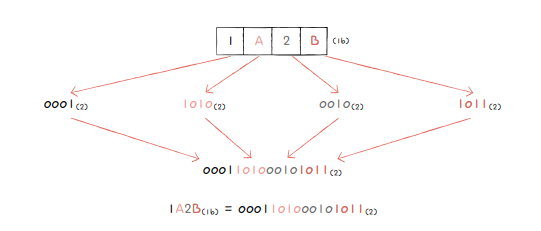
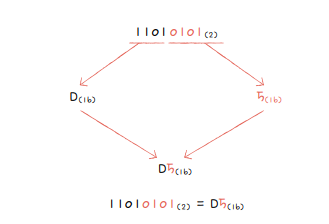
2. 0과 1로 문자를 표현하는 방법
Key Word: 문자 집합 / 아스키 코드 / EUC-KR / 유니코드
컴퓨터가 문자를 이해하고 표현하는 다양한 방법
문자 집합과 인코딩
문자 집합(character set)
- 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
- 문자 집합 {a, b, c, d, e} -> a, b,c, d, e 이해 O / f, g 같은 문자는 이해 X
문자 인코딩(character encoding)
- 코드화하는 과정
- 문자 -> 컴퓨터가 이해할 수 있는 0과 1로 변환
- 인코딩 후 0과 1로 이뤄진 결과값 = 문자 코드
문자 디코딩(character decoding)
- 코드를 해석하는 과정
- 0과 1로 이뤄진 문자 코드 -> 사람이 이해할 수 있는 문자로 변환하는 과정
아스키 코드
아스키(ASCII; American Standard Code for Information Interchange)
- 초창기 문자 집합 중 하나
- 영어 알파벳, 아라비아 숫자, 일부 특수 문자 포함
아스키 문자
- 아스키 문자 집합에 속한 문자
- 7비트로 표현 -> 표현할 수 있는 정보 가짓수 $ 2^7 $ = 128개의 문자를 표현(0 ~ 127)
- 8비트 중 1비트는 오류 검출 위해 사용(패리티 비트; Parity bit)
아스키 코드
- 아스키 문자에 대응된 고유한 수 = 아스키 코드
=> 아스키 문자 -> 아스키 코드로 인코딩
'A' -> 십진수 65(이진수 $1000001_{(2)}$)
'a' -> 십진수 97(이진수 $1100001_{(2)}$)
특수 문자 ! -> 십진수 33(이진수 $100001_{(2)}$)
코드 포인트(code point): 글자에 부여된 고유한 값
<아스키 코드 장단점>
- (+) 매우 간단하게 인코딩
- (-) 한글, 아스키 문자 집합 외의 문자, 특수문자 표현 X
-> 다양한 문자 표현 위해 아스키 코드 + 1 = 8비트 의 확장 아스키(extended ASCII)
But, 표현 가능한 문자의 수 256개 -> 여전히 부족
=> 한국 인코딩 방식: EUC-KR
<한글 인코딩 2가지 방식>
- 완성형 인코딩
- 초성, 중성, 종성의 조합으로 이뤄진 완성된 하나의 글자에 고유한 코드를 부여하는 이코딩 방식
- '가' -> 1, '나' -> 2, '다' -> 3
- 조합형 인코딩
- 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열 할당
-> 조합으로 하나의 글자 코드를 완성하는 인코딩 방식 - 초성, 중성, 종성에 해당하는 코드 합하여 하나의 글자를 만드는 인코딩 방식
- 초성을 위한 비트열, 중성을 위한 비트열, 종성을 위한 비트열 할당
EUC-KR
- KS X 1001, KS X 1003이라는 문자 집합을 기반으로 하는 대표적인 완성형 인코딩 방식
- 초성, 중성, 종성이 모두 결합된 한글 단어에 2바이트 크기의 코드 부여
- EUC-KR로 인코딩된 한글 한 글자 표현 -> 16비트 필요 => 4자리 16진수로 나타낼 수 있음
- 총 2,350개 정도의 한글 단어 표현 가능
- But, 모든 한글 표현 불가능_'쀍', '쀓', '믜' 같은 글자 표현 X
=> 마이크로소프트의 CP949(Code Page 949)
: EUC-KR의 확장된 버전 -> But, 한글 전체 표현 X
유니코드와 UTF-8
모든 나라 언어의 문자 집합과 인코딩 방식 통일되어 있음
= 모든 언어를 아우르는 문자 집합과 통일된 표준 인코딩 방식 O
-> 언어별로 인코딩하는 수고로움 덜 수 있음
유니코드(unicode)
- EUC-KR보다 훨씬 다양한 한글을 포함
- 대부분 나라의 문자, 특수문자, 화살표, 이모티콘까지 코드로 표현할 수 있는 통일된 문자 집합
- 여러 나라의 문자들 광범위하게 표현할 수 있는 통일된 문자 집합
- 현대 문자를 표현할 때 가장 많이 사용되는 표준 문자 집합
- UTF-8, UTF-16, UTF-32: 유니코드 문자에 부여된 값을 인코딩하는 방식
- UTF(Unicode Transformation Format): 유니코드를 인코딩 하는 방법
UTF-8
1바이트부터 4바이트까지의 인코딩 결과 만들어 냄
UTF-8로 인코딩한 값의 결과는 1, 2, 3, 4바이트가 될 수 있음
-> 몇 바이트가 될지는 유니코드 문자에 부여된 값에 범위에 따라 달라짐
| 첫 코드 포인트 | 마지막 코드 포인트 | 1바이트 | 2바이트 | 3바이트 | 4바이트 |
| 0000 | 007F | 0XXXXXXX | |||
| 0080 | 07FF | 110XXXXX | 10XXXXXX | ||
| 0800 | FFFF | 1110XXXX | 10XXXXXX | 10XXXXXX | |
| 10000 | 10FFFF | 11110XXX | 10XXXXXX | 10XXXXXX | 10XXXXXX |
유니코드 문자에 부여된 값의 범위가 0부터 $007F_{(16)}$까지는 1바이트로 표현
유니코드 문자에 부여된 값의 범위가 $0080_{(16)}$부터 $07FF_{(16)}$까지는 2바이트로 표현
유니코드 문자에 부여된 값의 범위가 $0800_{(16)}$부터 $FFFF_{(16)}$까지는 3바이트로 표현
유니코드 문자에 부여된 값의 범위가 $10000_{(16)}$부터 $10FFFF_{(16)}$까지는 4바이트로 표현
'한'에 부여된 값 $D55C_{(16)}$, '글'에 부여된 값 $AE00_{(16)}$
-> 두 글자 모두 $0800_{(16)}$부터 $FFFF_{(16)}$ 사이
=> UTF-8로 인코딩하면 3바이트로 표현될 것을 예상
-> 이진수로 표현
11101101 10010101 10011100$_{(2)}$
11101010 10111000 10000000$_{(2)}$
출처
[한빛미디어] 혼자 공부하는 컴퓨터 구조+운영체제
좋은 개발자는 컴퓨터를 분석의 대상으로 바라볼 뿐, 두려워하지 않는다!‘전공서가 너무 어려워서 쉽게 배우고 싶을 때’, ‘개발자가 되고 싶은데 뭐부터 봐야 하는지 모를 때’ ‘기술 면접
hongong.hanbit.co.kr
'📓 > 컴퓨터구조 | 운영체제' 카테고리의 다른 글
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 06 메모리와 캐시 메모리 (0) | 2024.01.08 |
|---|---|
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 05 CPU 성능 향상 기법 (0) | 2024.01.08 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 04 CPU의 작동 원리 (0) | 2024.01.08 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 03 명령어 (0) | 2024.01.05 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 01 컴퓨터 구조 시작하기 (0) | 2024.01.05 |