
Chapter 03 명령어
1. 소스 코드와 명령어
Key Word: 고급언어 / 저급 언어 / 기계어 / 어셈블리어 / 컴파일 언어 / 인터프리터 언어
컴퓨터: 명령어를 처리하는 기계(01장)
-> 명령어: 컴퓨터를 실질적으로 작동시키는 매우 중요한 정보
소스코드 -> 컴퓨터 내부에서 명령어로 변환
고급 언어와 저급 언어
컴퓨터: C, C++, Java, Python과 같은 프로그래밍 언어 이해 X
프로그램 만들 때 사용하는 프로그래밍 언어 != 컴퓨가 이해하는 언어
-> 사람이 이해하고 작성하기 쉽게 만들어진 언어
고급 언어 -변환-> 저급 언어
고급 언어(high-level programming language)
- 사람을 위한 언어
- 대부분의 프로그래밍 언어
- 이해하고 작성하기 쉬움
- 더 나은 가독성
- 변수나 함수 같은 편리한 문법 제공 -> 복잡한 프로그램 구현 가능
저급 언어(low-level programming language)
- 컴퓨터가 직접 이해하고 실행할 수 있는 언어
- 기계어(machine code)
- 0과 1의 명령어 비트로 이뤄진 언어
- 0과 1로 이뤄진 명령어 모음
- 가독성 위해 십육진수(0 ~ 9, A ~ F)로 표현하기도 함
- 오로지 컴퓨터만을 위해 만들어진 언어 -> 사람 의미 이해 어려움
- 어셈블리어(assembly language)
- 0과 1로 표현된 명령어(기계어)를 사람이 읽기 편한 상태로 변역한 언어
기계어 어셈블리어
0101 0101 -> push rbp
0101 1101 -> pop rbp
1100 0011 -> ret
Q: 왜 저급 언어 알아야 할까? 개발자 고급 언어로 소스 코드 작성 -> 알아서 저급 언어로 변환되어 실행
=> 일부러 저급 언어로 개발할 일 없지 않나?
A: 어떤 개발자 희망하는지 -> 저급 언어의 중요성 달라짐
하드웨어와 밀접하게 맞닿아 있는 프로글매을 개발하는 개발자(임베디드, 게임, 정보 보안 등): 어셈블리어 이용 ↑
어셈블리어: 작성의 대상 + 관찰의 대상
-> 컴퓨터가 프로그램을 어떤 과정으로 실행하는지 = 프로그램이 어떤 절차로 작동하는지 추적, 관찰 가능
컴파일 언어와 인터프리터 언어
<고급 언어 -> 저급 언어 변환 방식>

- 컴파일 방식
- 컴파일 언어: 컴파일 방식으로 작동하는 프로그래밍 언어
- 인터프리트 방식
- 인터프리터 언어: 인터프리트 방식으로 작동하는 프로그래밍 언어
컴파일 언어
- 컴파일러에 의해 소스 코드 전체가 저급 언어로 변환되어 실행되는 고급 언어
- 대표적인 컴파일 언어: C
- 컴파일(compile): 컴파일 언어로 작성된 소스 코드 전체 -> 저급 언어로 변환
- 컴파일러(compiler): 컴파일 수행해 주는 도구
- 소스 코드에 문법적 오류 없는지, 실행 가능한 코드인지, 불필요한 코드 없는지 확인
- 오류 하나라도 발견 시 소스 코드는 컴파일 실패
- 목적 코드(object code): 컴파일러 ~> 저급 언어로 변환된 코드
(고급 언어) 소스 코드 -(컴파일) 컴파일러-> (저급 언어) 목적 코드
인터프리터 언어
- 인터프리터에 의해 소스 코드가 한 줄씩 (저급 언어로 변환되어) 실행되는 고급 언어
- 대표적인 인터프리터 언어: Python
- 소스 코드 한 줄씩 한 줄씩 차례로 실행
- <-> 컴파일 언어: 소스 코드 전체 -> 저급 언어로 변환
- 인터프리터(interpreter): 소스 코드 한 줄씩 저급 언어로 변환하여 실행해 주는 도구
- 소스 코드 전체 저급 언어로 변환하는 시간 기다릴 필요 X
- 소스 코드 N번째 줄에 문법 오류 -> N-1번째 줄까지 올바르게 수행
- <-> 컴파일 언어: 소스 코드 내 오류 하나라도 O -> 컴파일 불가
- 컴파일 언어보다 느림
- 컴파일 ~> 결과물 = 목적 코드: 저급 언어, 인터프리터 언어: 소스 코드 마지막까지 한 줄씩 저급 언어로 해석 및 실행
하나의 프로그래밍 언어가 반드시 둘 중 하나의 방식만으로 작동 X
= 컴파일 언어라고 해서 인터프리트 불가능 or 인터프리트가 가능한 언어라고 해서 컴파일 불가능 X
=> 모든 프로그래밍 언어를 칼로 자르듯 구분 X
고급 언어가 저급 언어로 변환되는 대표적인 방법에는 컴파일 방식과 인터프리트 방식이 있음
고급 언어 -(컴파일/인터프리트)-> 저급 언어
= 독일어 모르는 친구에게 독일어로 쓰인 책 설명해 주는 것
컴파일 언어: 독일어로 쓰인 책(소스 코드) -> 한국어로 번역한 뒤 번역한 책(목적 코드)을 친구에게 건네주는 방식
=> 컴파일 시간 기다려야 하지만 번역 책 건네받으면 빠르게 읽을 수 있음
인터프리터 언어: 독일어로 쓰인 책 한 줄씩 한국어로 설명해주는 방식
C언어 컴파일과정
`test.c` -(전처리기 → 컴파일러 → 어셈블러 → 링커(linker))-> `test.exe`
- 전처리기(preprocessor): `test.i`
- 본격적으로 컴파일하기 전에 처리할 작업들
- 외부에 선언된 다양한 소스 코드, 라이브러리 포함(e.g. `#include`)
- 프로그래밍 편의를 위해 작성된 매크로 변환(e.g. `#define`)
- 컴파일할 영역 명시(e.g. `#if`, `#ifdef`, …)
- 컴파일러(compiler): `test.s`
- 전처리가 완료 돼도 여전히 소스 코드
- 저급 언어(어셈블리어)로 변환
- 어셈블러(assembler): `test.o`
- 어셈블리어 → 기계어
- 목적 코드 포함하는 파일
목적 파일 vs. 실행 파일
- 목적 파일
- 목적 코드로 이뤄진 파일
- 목적 코드: 컴퓨터가 이해하는 저급 언어
- 실행 파일
- 실행 코드로 이뤄진 파일
- 윈도우의 `.exe` 확장자 가진 파일
목적 코드 -링킹(linking)-> 실행 파일
링킹: 연결 작업
컴파일 언어로 `helper.c`와 `main.c`라는 2개의 소스 코드 작성
1. `helper.c` 안에는 'HELPER_더하기'라는 기능 구현되어 있음
2. `main.c`는 `helper.c`에 구현된 'HELPER_더하기' 기능
+ 프로그래밍 언어가 기본적으로 제공하는 '화면_출력'이라는 기능 가져다 씀
목적 파일은 각각 `helper.o`와 `main.o`
=> Q: `main.o`는 저급 언어니까 바로 실행 가능?
A: 실행할 수 없음. `main.o`는 `main.c`의 내용이 그대로 저급 언어로 변환된 파일일 뿐
`main.c`에 없는 'HELPER_더하기' or '화면_출력'은 어떻게 실행하는지 알지 못함
=> `main.o`가 실행되면 `main.o`에 없는 외부 기능을 `main.o`와 연결 짓는 작업 필요
2. 명령어의 구조
Key Word: 명령어 / 연산 코드 / 오퍼랜드 / 주소 지정 방식
연산 코드와 오퍼랜드
명령어
- 연산 코드(operation code) = 연산자
- 명령어가 수행할 연산
- 연산 코드 필드: 연산 코드가 담기는 영역
- 오퍼랜드(operand) = 피연산자
- 연산에 사용할 데이터
- 연산에 사용할 데이터가 저장된 위치
- 오퍼랜드 필드: 오퍼랜드가 담기는 영역
연산 코드
<유형 4가지>
- 데이터 전송
- MOVE: 데이터 옮기기
- STORE: 메모리에 저장
- LOAD(FETCH): 메모리에서 CPU로 데이터 가져오기
- PUSH: 스택에 데이터 저장
- POP: 스택의 최상단에 데이터 가져오기
- 산술/논리 연산
- ADD(덧셈) / SUBTRACT(뺄셈) / MULTIPLY(곱셈) / DIVIDE(나눗셈)
- INCREMENT(오퍼랜드에 1 더하기)/ DECREMENT(오퍼랜드에 1 빼기)
- ADD, SUBTRACT 보다 빠름
- AND / OR / NOT: AND / OR / NOT 연산을 수행
- COMPARE: 두 개의 숫자 or TRUE / FALSE 값을 비교
- 제어 흐름 변경
- JUMP: 특정 주소로 실행 순서 옮기기
- CONDITIONAL JUMP: 조건에 부합할 때 특정 주소로 실행 순서 옮기기
- HALT: 프로그램 실행 멈추기
- CALL: 되돌아올 주소를 저장한 채 특정 주소로 실행 순서 옮기기
- RETURN: CALL을 호출할 때 저장했던 주소로 돌아가기
- 입출력 제어
- READ(INPUT): 특정 입출력 장치로부터 데이터 읽기
- WRITE(OUTPUT): 특정 입출력 장치로 데이터 쓰기
- START IO: 입출력 장치를 시작
- TEST IO: 입출력 장치의 상태를 확인
오퍼랜드
연산에 사용할 데이터 or 연산에 사용할 데이터가 저장된 위치
-> 오퍼랜드 필드에 데이터(숫자와 문자 등) or 메모리 or 레지스터 주소 올릴 수 O
But, 연산에 사용할 데이터를 직접 명시하기 보다 연산에 사용할 데이터가 저장된 위치(메모리 주소 or 레지스터 이름) 담김
=> 오퍼랜드 필드 = 주소 필드
- 0-주소 명령어(오퍼랜드가 없는 경우)
- 연산 코드
- 1-주소 명령어(오퍼랜드 1개인 경우)
- 연산 코드 + 오퍼랜드
- 2-주소 명령어(오퍼랜드 2개인 경우)
- 연산 코드 + 오퍼랜드 + 오퍼랜드
- 3-주소 명령어(오퍼랜드 3개인 경우)
- 연산 코드 + 오퍼랜드 + 오퍼랜드 + 오퍼랜드
주소 지정 방식
Q: 왜 오퍼랜드 필드에 메모리 or 레지스터의 주소를 담는 건지?
그냥 <연산 코드, 연산 코드에 사용될 데이터> 형식으로 명령어 구성하면 되지 않나?
A: 명령어 길이 때문
하나의 명령어가 n비트로 구성, 그 중 연산 코드 필드가 m비트
-> 오퍼랜드 필드에 가장 많은 공간을 할당할 수 있는 1-주소 명령어라 해도 오퍼랜드 길이 = 연산 코드만큼의 길이 뺀 n-m비트
2-주소 명령어, 3-주소 명령어 -> 오퍼랜드 크기 더욱 ↓
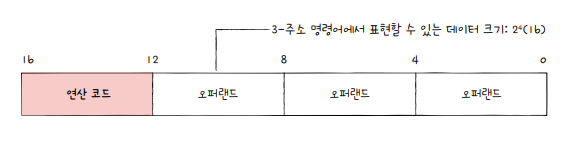

IF 명령어 크기 166비트, 연산 코드 비트가 4비트인 2-주소 명령어
-> 오퍼랜드 필드당 6비트 정도밖에 안남음
= 하나의 오퍼랜드 필드로 표현할 수 있는 정보의 가짓수 $2^6$ 개
3-주소 명령어 -> 오퍼랜드 필드당 4비트 정도밖에 안남음
=> 하나의 오퍼랜드 필드로 표현할 수 있는 정보의 가짓수 $2^4$ 개
But, 오퍼랜드 필드 안에 메모리 주소 담긴다면 -> 데이터 크기 = 하나의 메모리 주소에 저장할 수 있는 공간만큼 커짐
한 주소에 16비트 저장할 수 있는 메모리
메모리안에 데이터 저장, 오퍼랜드 필드 안에 해당 메모리 명시
-> 표현할 수 있는 정보의 가짓수 $2^{16}$
유효 주소(effective address)
- 연산 코드에 사용할 데이터가 저장된 위치
- 연산의 대상이 되는 데이터가 저장된 위치
명령어 주소 지정 방식(addressing mode)
- 오퍼랜드 필드에 데이터가 저장된 위치를 명시할 때 연산에 사용할 데이터 위치를 찾는 방법
- 유효 주소 찾는 방법
<주소 지정 방식 5가지>
즉시 주소 지정 방식(immediate addressing mode)
- (연산 코드 + 연산에 사용할 데이터)
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식
- 가장 간단한 형태의 주소 지정 방식
- (-) 데이터의 크기 작아짐
- (+) 다른 주소 지정 방식 보다 빠름
- 연산에 사용할 데이터를 메모리 or 레지스터로부터 찾는 과정 X
직접 주소 지정 방식(direct addressing mode)
- (연산 코드 + 유효 주소) -> 메모리) 연산에 사용할 데이터
- 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식
- (+) 오퍼랜드 필드에서 표현할 수 있는 데이터의 크기는 즉시 주소 지정 방식보다 커짐
- (-) 여전히 유효 주소를 표현할 수 있는 범위: 연산 코드의 비트 수만큼 줄어듬
- = 표현할 수 있는 오퍼랜드 필드의 길이가 연산 코드의 길이만큼 짧아짐
-> 표현할 수 있는 유효 주소에 제한 생길 수 있음
- = 표현할 수 있는 오퍼랜드 필드의 길이가 연산 코드의 길이만큼 짧아짐
간접 주소 지정 방식(indirect addressing mode)
- (연산 코드 + 유호 주소의 주소) -> 메모리) 유효 주소 -> 연산에 사용할 데이터
- 유효 주소의 주소를 오퍼랜드 필드에 명시
- (+) 직접 주소 지정 방식보다 표현할 수 있는 유효 주소의 범위 넓어짐
- (-) 2번의 메모리 접근 필요 -> 속도 ↓
- 때때로 연산에 사용할 데이터가 레지스터에 저장되는 경우 O
- -> 레지스터 주소 지정 방식 or 레지스터 간접 주소 지정 방식 사용
레지스터 주소 지정 방식(register addressing mode)
- (연산 코드 + 유효 주소) -> CPU(레지스터)) 연산에 사용할 데이터
- 직접 주소 지정 방식과 비슷하게 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방법
- (+) 직접 주소 지정 방식보다 빠르게 데이터에 접근 가능
- CPU 외부에 있는 메모리에 접근 속도 < CPU 내부에 있는 레지스터에 접근 속도
- (-) 레지스터 크기에 제한 생길 수 있음
- ~= 직접 주소 지정 방식
레지스터 간접 주소 지정 방식(register indirect addressing mode)
- (연산 코드 + 유효 주소를 저장한 레지스터) -> CPU(레지스터)) 유효 주소 -> 메모리) 연산에 사용할 데이터
- 연산에 사용할 데이터를 메모리에 저장, 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법
- 유효 주소 찾는 과정
- ~= 간접 주소 지정 방식
- (+) 메모리에 접근하는 횟수가 1번으로 줄어듬
- 레지스터 간접 주소 지정 방식 속도 > 간접 주소 지정 방식
- 메모리에 접근하는 속도 < 레지스터에 접근하는 속도
<정리_오퍼랜드 필드에 명시하는 값>
- 즉시 주소 지정 방식: 연산에 사용할 데이터
- 직접 주소 지정 방식: 유효 주소(메모리 주소)
- 간접 주소 지정 방식: 유효 주소의 주소
- 레지스터 주소 지정 방식: 유효 주소(레지스터 이름)
- 레지스터 간접 주소 지정 방식: 유효 주소를 저장한 레지스터
+스택과 큐
스택(stack)
- 한쪽 끝이 막혀 있는 통과 같은 저장 동로
- LIFO(Last In First Out, 리포) 자료구조 = 후입선출
- 나중에 저장한 데이터를 가장 먼저 빼내는 데이터 관리 방식
- 1-2-3-4-5 순으로 데이터 저장 -> 데이터 빼낼 때는 5-4-3-2-1 순으로
- PUSH: 스택에 새로운 데이터 저장하는 명령어
- POP: 스택에 저장된 데이터를 꺼내는 명령어
- 수행 -> 스택의 최상단에 있는(Last In), 마지막으로 저장한 데이터부터(First Out) 꺼냄
큐(queue)
- 양쪽이 뚫려 있는 통과 같은 저장 공간
- 한쪽으로는 데이터 저장, 다른 한쪽으로는 먼저 저장한 순서대로 데이터 빼냄
- FIFO(First In First Out, 피포) 자료구조 = 선입선출
- 가장 먼저 저장된 데이터부터 빼내는 데이터 관리 방식
출처
[한빛미디어] 혼자 공부하는 컴퓨터 구조+운영체제
좋은 개발자는 컴퓨터를 분석의 대상으로 바라볼 뿐, 두려워하지 않는다!‘전공서가 너무 어려워서 쉽게 배우고 싶을 때’, ‘개발자가 되고 싶은데 뭐부터 봐야 하는지 모를 때’ ‘기술 면접
hongong.hanbit.co.kr
'📓 > 컴퓨터구조 | 운영체제' 카테고리의 다른 글
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 06 메모리와 캐시 메모리 (0) | 2024.01.08 |
|---|---|
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 05 CPU 성능 향상 기법 (0) | 2024.01.08 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 04 CPU의 작동 원리 (0) | 2024.01.08 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 02 데이터 (0) | 2024.01.05 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 01 컴퓨터 구조 시작하기 (0) | 2024.01.05 |