
728x90
반응형
Chapter 07 보조기억장치
1. 다양한 보조기억장치
하드 디스크/ 플래터/ 데이터 접근 시간/ 플래시 메모리/ 페이지/ 블록
보조기억장치: 하드 디스크, 플래시 메모리(ex. USB 메모리, SD 카드, SSD)
하드 디스크(HDD; Hard Disk Drive) = 자기 디스크(magnetic disk)
자기적인 방식으로 데이터를 저장하는 보조기억장치
-
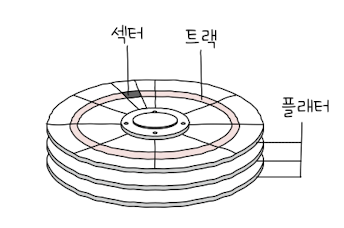
- 트랙(track): 플래터를 여러 동심원으로 나눴을 때 그중 하나의 원
- 섹터(sector)
- 트랙을 여러 조각으로 나눈 것 중 한 조각
- 하드 디스크의 가장 작은 전송 단위
- 블록(block): 하나 이상의 섹터
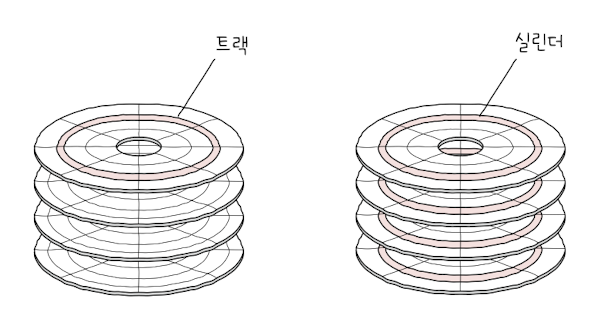
- 실린더(cylinder)
- 여러 겹의 플래터 상에서 같은 트랙이 위치한 곳을 모아 연결한 논리적 단위
- 연속된 정보는 한 실린더에 기록 -> 디스크 암을 움직이지 x 바로 데이터 접근 O
- -> 한 플래터 -> 동심원으로 나눈 공간: 트랙/ 같은 트랙끼리 연결한 원통 모양 공간: 실린더
=> 트랙과 섹터로 나뉘고, 같은 트랙 모여 실린더 이룸플래터(platter):실질적으로 데이터가 저장되는 곳
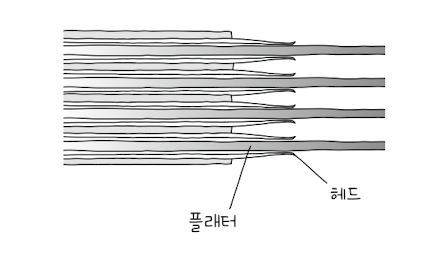
CD나 LP에 비해 많은 양의 데이터 저장 => 여러 겹의 양면 플래터(위아래 플래터당 2개의 헤드 사용)
- 스핀들(spindle): 플래터를 회전시키는 구성 요소
- RPM(Revolution Per Minute): 스핀들이 플래터를 돌리는 속도, 분당 회전수
- ex. RPM이 15,00인 하드 디스크: 1분에 15,000바퀴를 회전하는 하드 디스크
- RPM(Revolution Per Minute): 스핀들이 플래터를 돌리는 속도, 분당 회전수
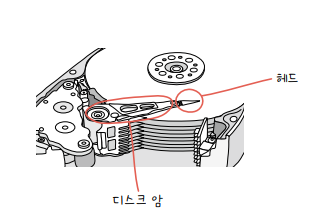
- 헤드(head): 플래터를 대상으로 읽고 쓰는 구성 요소, 플래터 위 미세하게 떠 있는 채로 데이터 읽고 씀
- 디스크 암(disk arm): 헤드를 원하는 위치로 이동시킴

하드 디스크가 저장된 데이터에 접근하는 시간
- 탐색 시간(seek time): 접근하려는 데이터가 저장된 트랙까지 헤드를 이동시키는 시간
- 회전 지연(rotational latency): 헤드가 있는 곳으로 플래터를 회전시키는 시간
- 전송 시간(transfer time): 하드 디스크와 컴퓨터 간의 데이터를 전송하는 시간
- 단일 헤드 디스크(single-head disk) = 이동 헤드 디스크(movable-head disk)
- 플래터의 한 명당 헤드가 하나씩 달려 있는 하드 디스크
- 다중 헤드 디스크(multiple-head disk) = 고정 헤드 디스크(fixed-head disk)
- 헤드가 트랙별로 여러 개 달려 있는 하드 디스크
- 트랙마다 헤드 O -> 탐색 시간 X => 탐색 시간: 0 = 헤드 움직일 필요 X
플래시 메모리(flash memory)
- NAND 메모리: NAND 연산을 수행하는 회로(NAND 게이트) 기반으로 만들어진 메모리, 대용량 저장 장치로 많이 사용
- NOR 플래시 메모리: NOR 연산을 수행하는 회로(NOR 게이트) 기반으로 만들어진 메모리
- 전기적으로 데이터를 읽고 쓸 수 있는 반도체 기반의 저장 장치
- ex. USB 메모리, SD 카드, SSD
- 하나의 셀(cell)에 몇 비트 저장할 수 있는지 -> 플래시 메모리 종류
셀: 메모리에서 데이터를 저장하는 가장 작은 단위 -> 모여서 MB, GB, TB 용량 갖는 저장 장치가 됨
=> 플래시 메모리의 수명, 속도, 가격에 영향 미침- SLC(Single Level Cell): 한 셀(집)에 1비트(사람) 저장 = 한 집에 1명
- MLC(Multiple Level Cell): 한 셀에 2비트 저장 = 한 집에 2명
- TLC(Triple-Level Cell): 한 셀에 3비트 저장 = 한 집에 3명
| 구분 | SLC | MLC | TLC |
| 셀당 bit | 1bit | 2bit | 3bit |
| 수명 | ↑ | 보통 | ↓ |
| 읽기/쓰기 속도 | 빠르다 | 보통 | 느리다 |
| 용량 대비 가격 | ↑ | 보통 | ↓ |
- 읽기/쓰기 단위(페이지) != 삭제 단위(블록)
- 셀 -> 페이지(page) -> 블록(block) -> 플레인(plane) -> 다이(die)
페이지 상태
- Free 상태: 어떠한 데이터도 저장 X 새로운 데이터 저장할 수 있는 상태
- Valid 상태: 이미 유효한 데이터를 저장하고 있는 상태
- 덮어쓰기 X(vs. 하드 디스크) -> 새 데이터 저장 X
- Invalid 상태: 쓰레기값이라 부르는 유효하지 X 데이터 저장하고 있는 상태
- 쓰레기값 저장하고 있는 공간은 사용 X 공간 But, 용량 차지 -> 용량 낭비
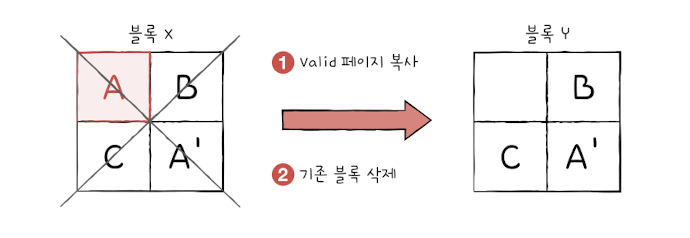
=> (해결) 가비지 컬렉션(garbage collection)- 유효한 페이지들만을 새로운 블록으로 복사
- 기존의 블록을 삭제하여 공간 정리
- 쓰레기값 저장하고 있는 공간은 사용 X 공간 But, 용량 차지 -> 용량 낭비
2. RAID의 정의와 종류
RAID/ RAID 0/ RAID 1/ RAID 4/ RAID 5/ RAID 6
Q. 1TB 하드디스크 4개 동시 사용 vs. 4TB 하드 디스크 하나 사용?
A. 1TB 하드디스크 4개 동시 사용
민감 정보 안전하게 관리 But, 보조기억장치에도 수명 O
RAID(Redundant Array of Independent Disks)
- 하드 디스크와 SSD를 사용하는 기술
- 데이터 안전성 or 성능 ↑ -> 여러 개의 보조기억장치를 1개의 보조기억장치처럼 사용하는 기술
RAID의 종류
RAID 레벨: RAID 구성 방법
RAID 0, RAID 1, RAID 2, RAID 3, RAID 4, RAID 5, RAID 6
(파생) RAID 10, RAID 50
- RAID 0: 여러 개의 보조기억장치에 데이터를 단순히 나눠 저장하는 구성 방식
- 번갈아 가며 데이터 저장 = 저장되는 데이터 -> 하드 디스크 개수만큼 나뉘어 저장
- 병렬로 균등하게 분산하여 저장
- 스트라입(strip): 줄무늬처럼 분산돼 저장된 데이터
- 스트라이핑(striping): 분산하여 저장하는 것
- (+) 데이터 분산되어 저장(스트라이핑) -> 저장된 데이터 읽고 쓰는 속도 ↑
- ex. RAID 0로 구성된 1TB 저장 장치 4개 속도가 이론상 4배 빠름
- (-) 저장된 정보 안전 X
- 1개 문제 -> 다른 모든 하드 디스크의 정보 읽는데 문제 생길 수 있음
- RAID 1 = 미러링(mirroring): 완전한 복사본을 만드는 방식
- 데이터 쓸 때 원본, 복사본 2곳에 씀 -> 쓰기 속도 ↓
- RAID 0 구성: 4TB 정보 저장/ RAID 1: 2TB 정보 저장
- (+) 복구 매우 간단
- (-) 하드 디스크 개수 한정 -> 사용 가능한 용량 ↓ -> ↑ 하드 디스크 필요 => 비용 ↑
- 데이터 쓸 때 원본, 복사본 2곳에 씀 -> 쓰기 속도 ↓
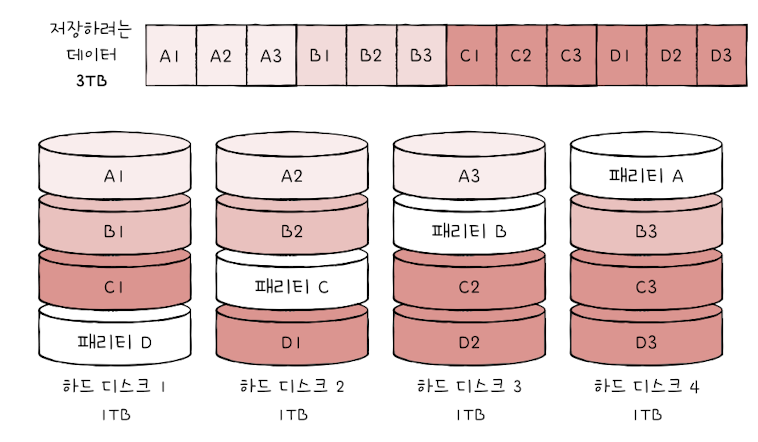
- RAID 4: (완전한 복사본 만드는 대신) 패리티를 저장한 장치를 따로 두는 방식
- 패리티 비트(parity bit): 오류 검출하고 복구하기 위한 정보
본래 오류 검출용 정보(복구 불가능) But, RAID에서는 오류 복구도 가능 - 패리티를 저장한 장치 -> 다른 장치 오류 검출 -> 오류 O -> 복구
- (+) ↓ 하드 디스크로 데이터 안전하게 보관 O
- (-) 패리티를 저장한느 장치에 병목 현상 발생
-> 어떤 새로운 데이터가 저장될 때마다 패리티를 저장하는 디스크에도 데이터 쓰게 됨
- 패리티 비트(parity bit): 오류 검출하고 복구하기 위한 정보
- RAID 5: 패리티를 분산하여 저장하는 방식
- RAID 6: 서로 다른 2개의 패리티 두는 방식 = 오류 검출하고 복구할 수 있는 수단 2개
- 구성은 RAID 5
- (+) 안전한 구성
- (-) 새로운 정보 저장할 때마다 함께 저장할 패리티 2개 -> 쓰기 속도 ↓
- => 저장 속도 ↓, 데이터 안전하게 보관
=> Nested RAID: 여러 RAID 레벨을 혼합한 방식
ex. RAID 10 = RAID 0 + RAID 1/ RAID 50 = RAID 0 + RAID 5




추가
해밍 코드
- 에러 교정 코드
- 패리티 비트를 정보의 수에 따라 피룡한 수만큼 사용
-> 코드 그룹의 적당한 장소에 놓고, 패리티 비트 조합에 의해 에러 검출 및 교정을 수행하게 하는 코드 - $2^p >= m + P + 1$ (m: 정보 비트 수/ P: 패리티 수)
- IF. 해밍코드에 의해 구성된 코드: 16비트 -> $2^4 = 16$ => p=4, $16 >= m + 4 + 1$ -> m = 11
- 해밍 코드에서 패리티 비트의 자리: 1, 2, 4, 8, 16, ...
ex. 1011에 대한 짝수 해밍코드 (m = 4)
p = 3 ( $8 >= 4 + 3 + 1$)
h1 h2 h3 h4 h5 h6 h7 <- 해밍코드
p1 p2 D1 p3 D2 D3 D4
p1 p2 1 p3 0 1 1
p1: 1, 3, 5, 7에서 1의 개수가 짝수 p = 0
(-> p1위치에서부터 1칸씩 뜀/ 0를 검출로 표시했을 때 0x0x0x...)
p2: 2, 3, 6, 7에서 1의 개수가 짝수 p = 1
(-> p2위치에서부터 2칸씩 뜀/ 0를 검출로 표시했을 때 00xx00xx...)
p3: 4, 5, 6, 7에서 1의 개수가 짝수 p = 0
(-> p3위치에서부터 4칸씩 뜀/ 0를 검출로 표시했을 때 0000xxxx...)
=> 0110011
[컴퓨터구조] 패리티 비트와 해밍 코드
패리티 비트(parity bit)는 정보의 전달 과정에서 오류가 생겼는지를 검사하기 위해 추가되는 비트로, 1 bit의 오류를 찾아낼 수 있다.패리티 비트를 포함한 데이터에서 1의 개수가 짝수인지 홀수인
velog.io
출처
[한빛미디어] 혼자 공부하는 컴퓨터 구조+운영체제
좋은 개발자는 컴퓨터를 분석의 대상으로 바라볼 뿐, 두려워하지 않는다!‘전공서가 너무 어려워서 쉽게 배우고 싶을 때’, ‘개발자가 되고 싶은데 뭐부터 봐야 하는지 모를 때’ ‘기술 면접
hongong.hanbit.co.kr
728x90
반응형
'📓 > 컴퓨터구조 | 운영체제' 카테고리의 다른 글
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 09 운영체제 시작하기 (0) | 2024.07.09 |
|---|---|
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 08 입출력장치 (0) | 2024.01.08 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 06 메모리와 캐시 메모리 (0) | 2024.01.08 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 05 CPU 성능 향상 기법 (0) | 2024.01.08 |
| [혼자 공부하는 컴퓨터구조+운영체제] Chapter 04 CPU의 작동 원리 (0) | 2024.01.08 |